데이터 불러오기
저번시간에 불러왔던 데이터를 다시 불러오도록 하자.
mydata <- read.csv("examscore.csv", header = TRUE)
head(mydata)>> student_id gender midterm final
>> 1 1 F 38 46
>> 2 2 M 42 67
>> 3 3 F 53 56
>> 4 4 M 48 54
>> 5 5 M 46 39
>> 6 6 M 51 74분포의 중간 지점을 나타내는 평균과 중앙값
평균 (mean)
우리가 갖고 있는 데이터를 가장 잘 대표하는 값 하나를 뽑으라면 평균이라고 생각합니다. 평균을 구하는 방법은 각각의 데이터를 더한 후, 데이터의 갯수만큼으로 나줘주면 됩니다.
x <- 6:10
sum(x) / length(x) # or>> [1] 8mean(x)>> [1] 8Q. 중간고사의 평균은 어떻게 될까요?
mean(mydata$midterm)>> [1] 41.16667평균을 구한다는 것은 우리가 가진 데이터 분포의 가운데가 어디인지를 구한다고 생각하면 됩니다. 다음의 그래프를 생각해봅시다.
hist(mydata$midterm,
xlab = "중간고사 성적",
ylab = "빈도",
main = "중간고사 성적 분포")
abline(v = mean(mydata$midterm), col = "red")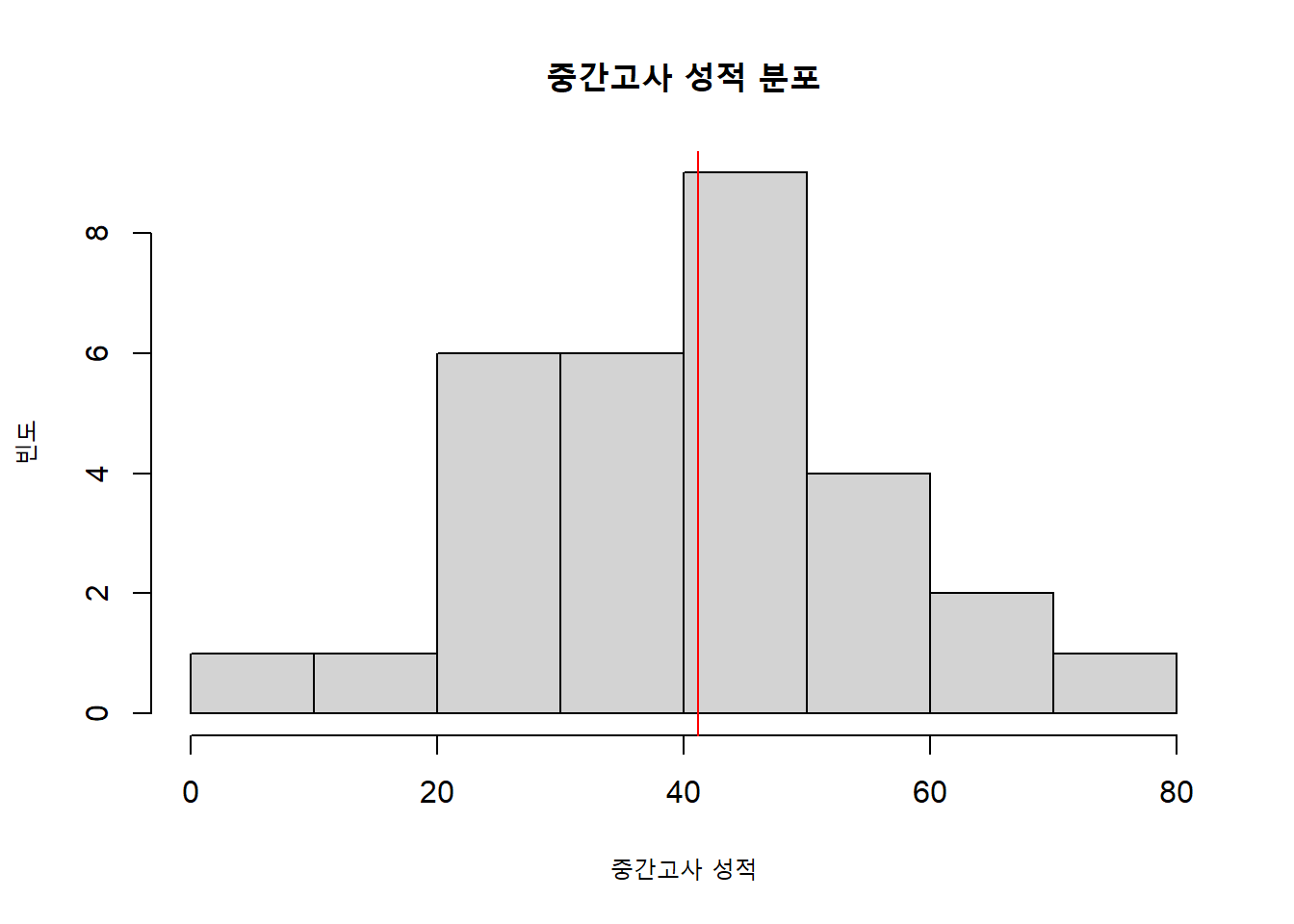
빨간색 세로선은 중간고사 점수에서 평균의 위치를 나타냅니다.
중앙값 (median)
통계에는 분포의 가운데를 나타내는 지표가 하나 더 있습니다. 바로 중앙값 입니다. 중앙값은 말 그대로 자료를 순서대로 나열한 후 정중앙에 위치한 데이터를 찾아 보여줍니다.
x <- 6:10
y <- 5:10 # n = 짝수
median(x)>> [1] 8median(y)>> [1] 7.5Q. 그렇다면 중간고사의 중앙값은 어떻게 될까요?
median(mydata$midterm)>> [1] 42hist(mydata$midterm,
xlab = "중간고사 성적",
ylab = "빈도",
main = "중간고사 성적 분포")
abline(v = mean(mydata$midterm), col = "red")
abline(v = median(mydata$midterm), col = "blue")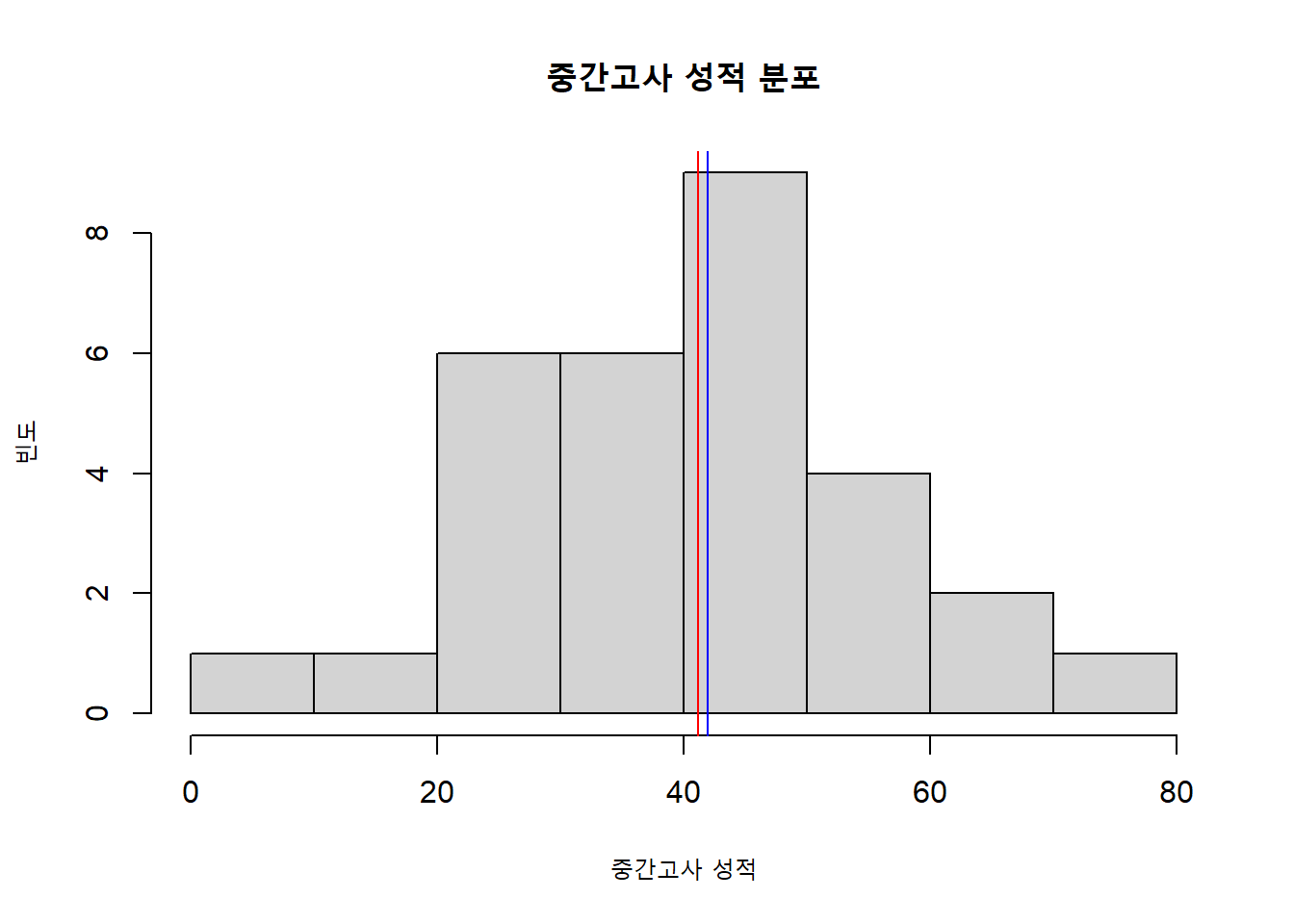
중앙값이 평균보다 살짝 큽니다만, 평균과 중앙값이 거의 같아서 분포의 중앙을 나타내 준다는 사실을 잘 알 수 있습니다. 그런데 이 두 값은 항상 이렇게 비슷할까요? 만약 그렇다면 굳이 따로 이름을 붙일 필요가 없을 것입니다. 학생 한 명의 중간고사 점수를 바꿔봅시다.
mydata$midterm[20] <- 100
mydata$midterm[22] <- 100
hist(mydata$midterm,
xlab = "중간고사 성적",
ylab = "빈도",
main = "중간고사 성적 분포")
abline(v = mean(mydata$midterm), col = "red")
abline(v = median(mydata$midterm), col = "blue")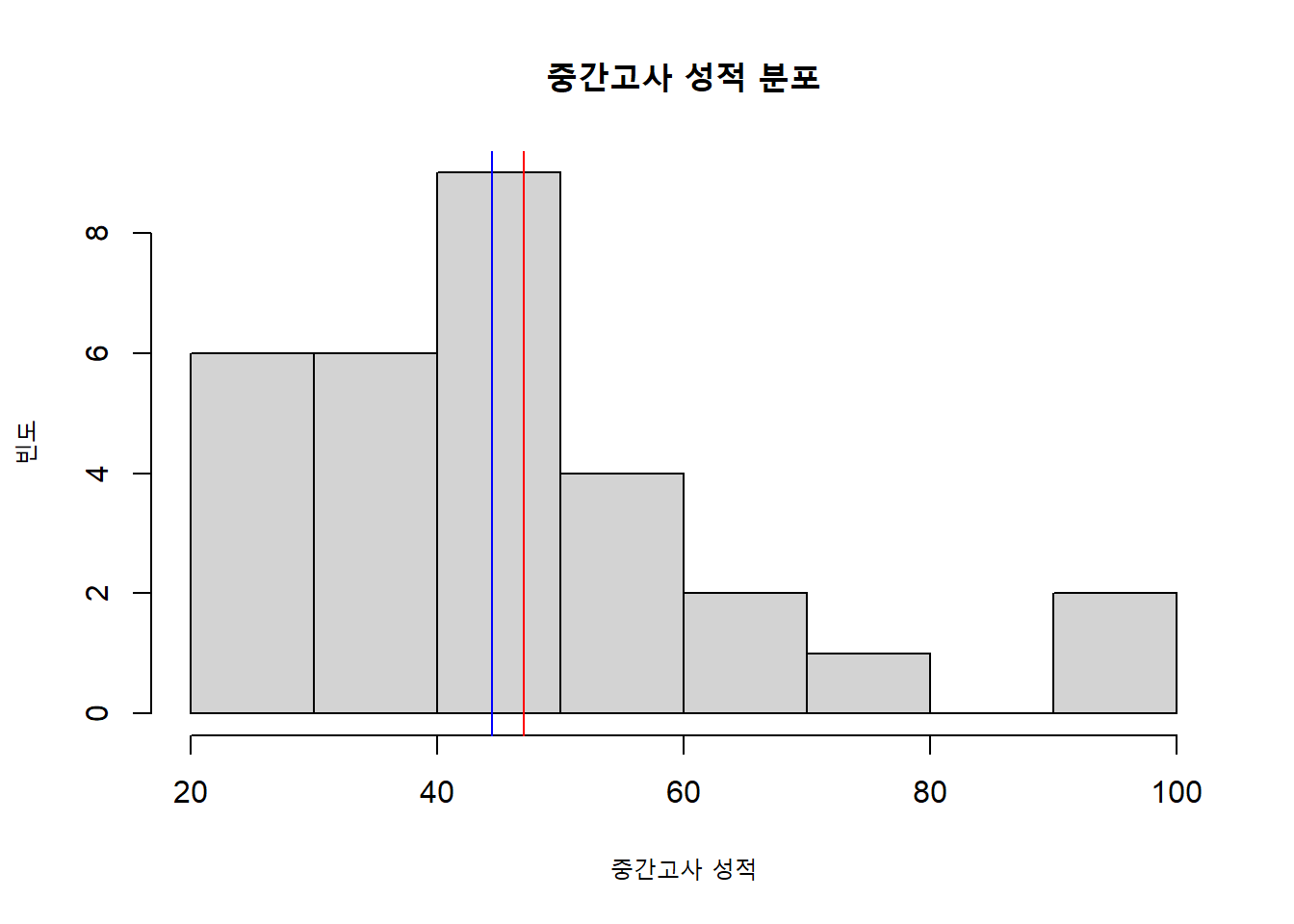
그래프가 그려진 범위는 80으로 똑같으므로, 우리가 바꾼 두 점수가 두 지표간의 차이를 벌려놓은 것이 확실합니다. 이전 그래프는 평균(빨간선)이 중앙값(파란선)보다 왼쪽에 위치해있었는데, 이젠 평균이 중앙값보다 더 큰 것을 알 수 있습니다. 이렇듯 두 지표는 분포의 형태에 따라서 각자 다르게 반응합니다.
분포의 산포된 정도를 나타내주는 분위수 (quantile)와 분산 (variance)
분위수들 (Quantiles)
R에는 quantile이라는 함수가 자료의 사분위수를 계산하는데에 쓰입니다. quantile 함수는 사분위수와 함께 통계에서 유명한 다섯가지 숫자를 통하여 분포의 특성을 요약해 줍니다.
quantile(mydata$midterm)>> 0% 25% 50% 75% 100%
>> 24.00 35.25 44.50 51.75 100.00결과를 보면, 중간고사 점수들의 분포를 다섯개의 숫자를 써서 나타내주는데, 0%에 대응되는 숫자가 자료에서의 최소값을 나타내는 숫자이며, 100%에 대응되는 숫자가 최대값을 나타냅니다.
# The first quartile (Q1)
quantile(mydata$midterm1)[2]>> 25%
>> NA# The first quartile (Q2)
quantile(mydata$midterm1)[2]>> 25%
>> NA# The third quartile (Q3)
quantile(mydata$midterm1)[4]>> 75%
>> NA25%와 75%에 대응하는 숫자들을 각각 제 1 사분위수와 제 3 사분위수라고 부르며, 제 2 사분위수는 중앙값을 의미합니다.
분산 (variance) 과 표준편차 (standard deviation)
분산은 평균과 함께 통계 전체를 대표하는 값이라고 해도 무방합니다. 분산의 제곱근을 표준편차라고 부르며, 분포가 얼마나 퍼져있는지를 나타내주는 지표입니다.
다음은 \(n\)개의 데이터가 있을때, 표본 분산 \(s^2\)를 구하는 식 입니다.
\[ s^{2}=\frac{\left(x_{1}-\overline{x}\right)^{2}+\left(x_{2}-\overline{x}\right)^{2}+...+\left(x_{n}-\overline{x}\right)^{2}}{n-1} \] 좀 더 간단하게는 다음과 같이 나타낼 수 있습니다.
\[ s^{2}=\frac{\sum_{i=1}^{n}\left(x_{i}-\overline{x}\right)^{2}}{n-1} \]
표준편차 \(s\)는 분산에 제곱근을 씌운 값을 나타냅니다. \[ s=\sqrt{\frac{\sum_{i=1}^{n}\left(x_{i}-\overline{x}\right)^{2}}{n-1}} \]
다음의 데이터를 생각해봅시다.
set.seed(1234)
x <- sample(1:10, 6)
x>> [1] 10 6 5 4 1 8위의 데이터를 가지고 표본 분산을 구하는 식을 R로 구현해 보면 다음과 같이 구할 수 있습니다.
x_bar <- mean(x)
sum((x - x_bar)^2) / (length(x) - 1)>> [1] 9.866667구한 값을 R에서 제공하는 함수의 결과값과 비교해보도록 합시다.
var(x); sd(x)>> [1] 9.866667>> [1] 3.141125히스토그램과 분산의 관계를 다음의 세가지 예를 통하여 생각해봅시다.
x <- rep(5, 10)
y <- c(1:10)
z <- c(3, 4, 5, 6, 7, 4, 5, 6, 5, 5)위의 자료들을 히스토그램을 이용하여 그려보면 다음과 같습니다.
hist(x, breaks = 0:10);
hist(y, breaks = 0:10);
hist(z, breaks = 0:10);
어떤 그래프가 가장 고르게 퍼져있나요? 각각의 데이터의 표준편사를 구해보면 다음과 같습니다.
sd(x); sd(y); sd(z)>> [1] 0>> [1] 3.02765>> [1] 1.154701중간고사 데이터의 분산과 표준편차는 다음과 같습니다.
var(mydata$midterm)>> [1] 351.1368sd(mydata$midterm)>> [1] 18.73864표준편차는 데이터와 같은 단위로 나타내어지기 때문에, 분산보다는 표준편차를 사용해서 분포의 퍼짐을 나타내는 것이 좋습니다.
'R > RSTAT101' 카테고리의 다른 글
| [RSTAT101] 7강. R에서 회귀분석 실행하기 (2) | 2023.06.10 |
|---|---|
| [RSTAT101] 6강. 회귀직선의 의미와 구하는 방법 (0) | 2023.06.10 |
| [RSTAT101] 5강. 상관계수의 의미와 시각화 (0) | 2023.06.10 |
| [RSTAT101] 4강. 사용자 정의함수와 최빈값 (0) | 2023.06.10 |
| [RSTAT101] 2강. 기초통계 그래프들 - 파이차트, 줄기-잎 그래프, 히스토그램, 상자그림 (0) | 2023.06.09 |




댓글