데이터 불러오기
저번시간에 불러왔던 데이터를 다시 불러오도록 하자.
mydata <- read.csv("examscore.csv", header = TRUE)
head(mydata)>> student_id gender midterm final
>> 1 1 F 38 46
>> 2 2 M 42 67
>> 3 3 F 53 56
>> 4 4 M 48 54
>> 5 5 M 46 39
>> 6 6 M 51 74데이터 열에 접근하기
$ 명령어는 불러온 데이터의 행에 접근 할 수 있도록 해줍니다. 다음은 불러온 mydata의 midterm1 열을 선택하는 코드입니다.
mydata$midterm>> [1] 38 42 53 48 46 51 48 43 28 38 50 29 27 36 29 34 35 46
>> [19] 39 9 76 15 63 28 49 42 24 52 65 52이전에 배웠던 대괄호 명령어 [] 를 사용해도 됩니다. 행과 열에 동시에 접근 할 수 있는 대신에 숫자를 사용해야 합니다.
mydata[,3]>> [1] 38 42 53 48 46 51 48 43 28 38 50 29 27 36 29 34 35 46
>> [19] 39 9 76 15 63 28 49 42 24 52 65 52mydata[1,] # the data related to the first student in the list>> student_id gender midterm final
>> 1 1 F 38 46table 함수를 이용한 파이 차트 그리기
파이 차트를 그리기 위해서는, 데이터 안에 몇 개의 데이터 포인트 들이 있는지 세어봐야 합니다. 이 경우 다음과 같이 table 함수를 사용하여 쉽게 데이터 구조를 파악 할 수 있습니다.
mytable <- table(mydata$gender)
mytable>>
>> F M
>> 10 20names(mytable)>> [1] "F" "M"위에서와 같이 table 함수의 결과값은 숫자와 그에 대응하는 열이름이 나오는 것을 확인 할 수 있는데, 이것을 이용하여 파이 차트의 변수명을 설정할 수 있습니다.
pie(mytable,
labels = names(mytable),
main="Pie Chart of the gender variable")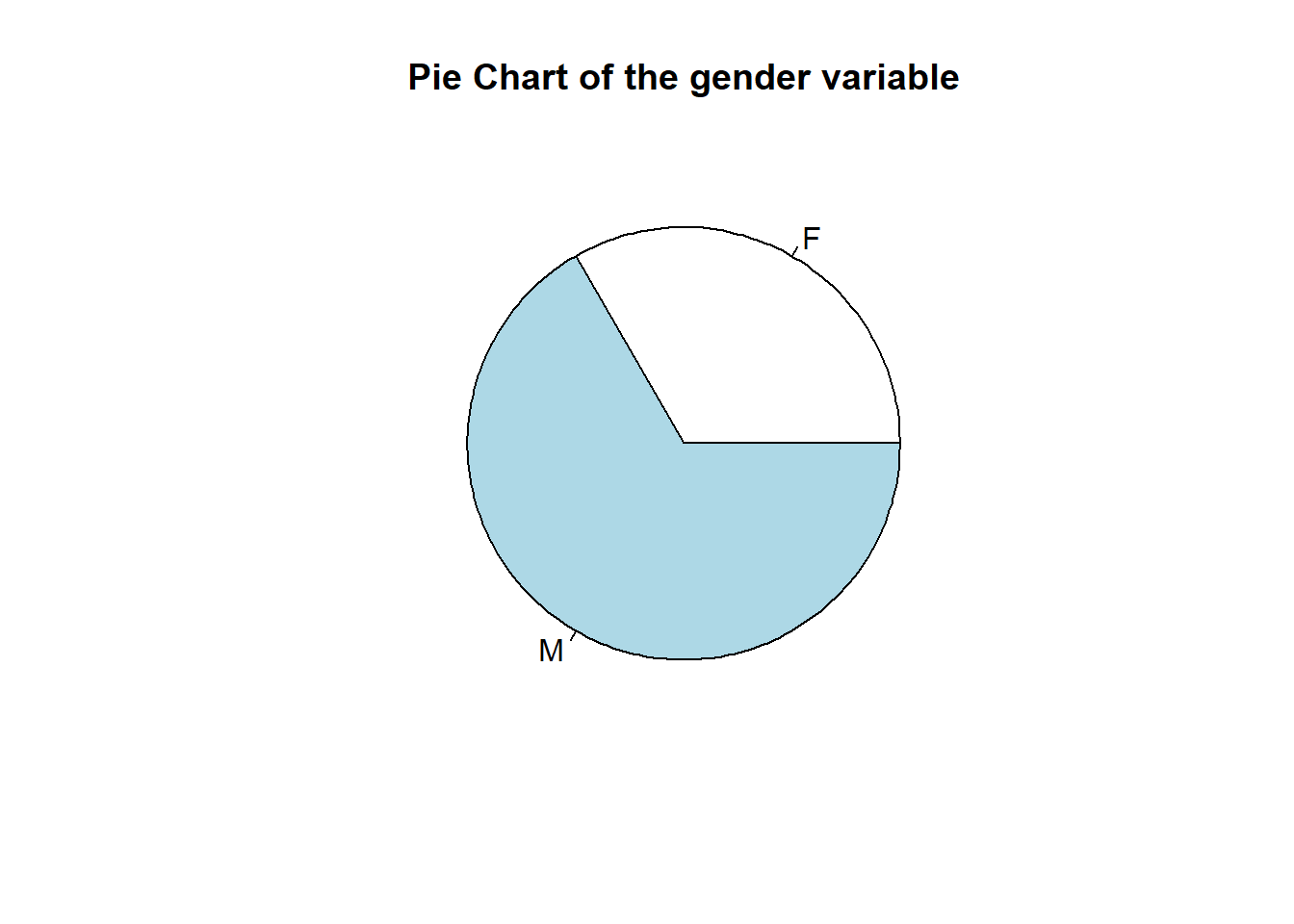
아니면, 다음과 같이 우리가 정하고 싶은 이름으로 설정할 수도 있습니다.
pie(mytable,
labels = c("여자", "남자"),
main="데이터 안의 성별 분포")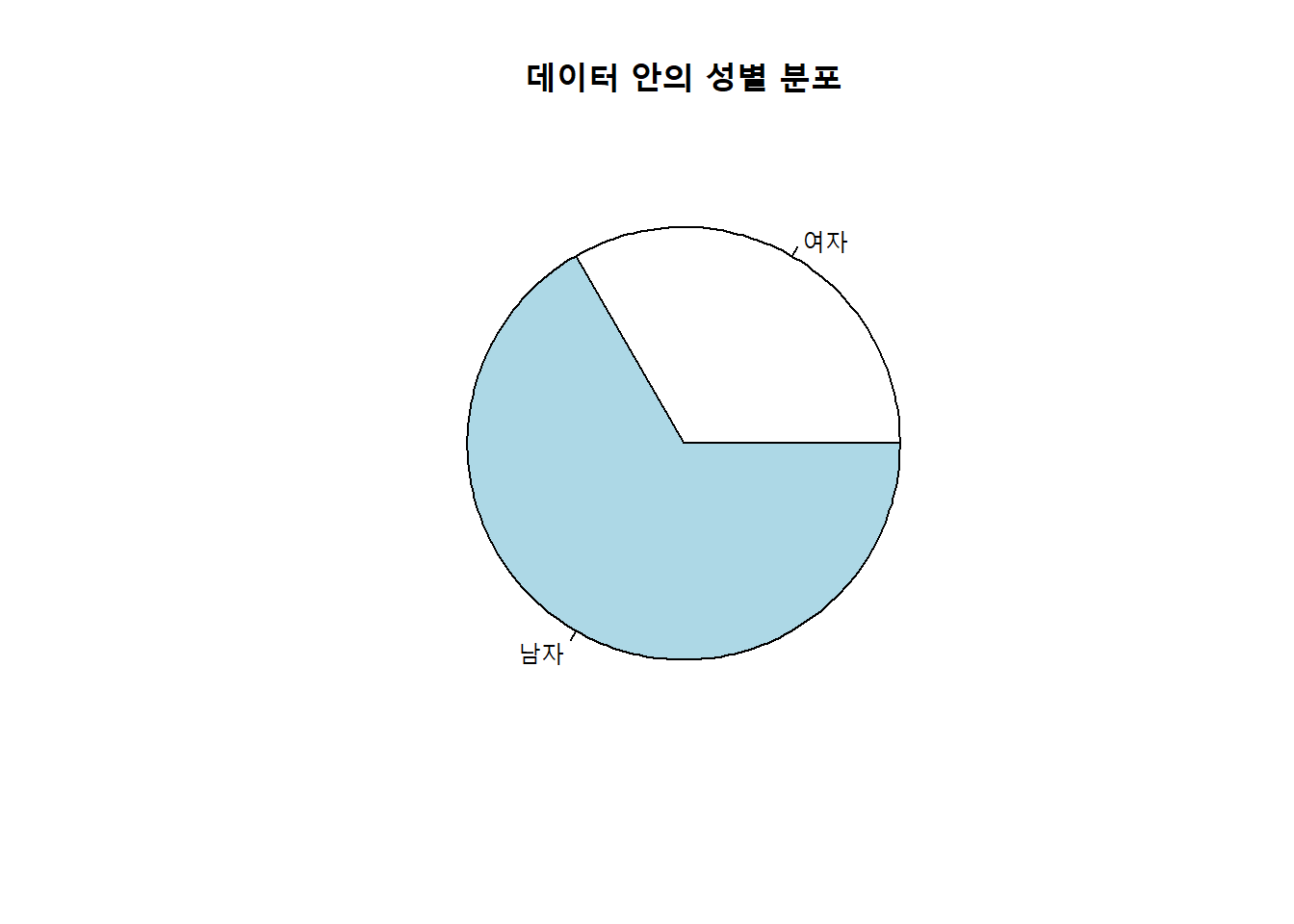
또한, 위의 labels의 옵션 안에 글자를 쓰면 파이차트 변수별로 이름이 정해지는 것을 이용하면, 다음과 같이 mytable의 정보를 추가 할 수도 있습니다.
pie(mytable,
labels = c("여자", "남자"),
main="데이터 안의 성별 분포")
text(0.3, 0.3, "33.33 %")
text(-0.3, -0.3, "66.67 %")
줄기-잎 그래프 (Stem and leaf plot)
R에서 제공하는 stem이라는 함수를 이용하여 줄기-잎 그래프를 그릴 수 있다.
stem(mydata$midterm)>>
>> The decimal point is 1 digit(s) to the right of the |
>>
>> 0 | 9
>> 1 | 5
>> 2 | 478899
>> 3 | 456889
>> 4 | 22366889
>> 5 | 01223
>> 6 | 35
>> 7 | 6위의 그래프는 줄기 단위가 10인 그래프인데, scale 옵션을 통하여 주어진 그래프의 줄기 단위를 바꿀 수 있다.
stem(mydata$midterm, scale = 0.5)>>
>> The decimal point is 1 digit(s) to the right of the |
>>
>> 0 | 95
>> 2 | 478899456889
>> 4 | 2236688901223
>> 6 | 356stem(mydata$midterm, scale = 2)>>
>> The decimal point is 1 digit(s) to the right of the |
>>
>> 0 | 9
>> 1 |
>> 1 | 5
>> 2 | 4
>> 2 | 78899
>> 3 | 4
>> 3 | 56889
>> 4 | 223
>> 4 | 66889
>> 5 | 01223
>> 5 |
>> 6 | 3
>> 6 | 5
>> 7 |
>> 7 | 6히스토그램 (Histogram)
hist(mydata$midterm)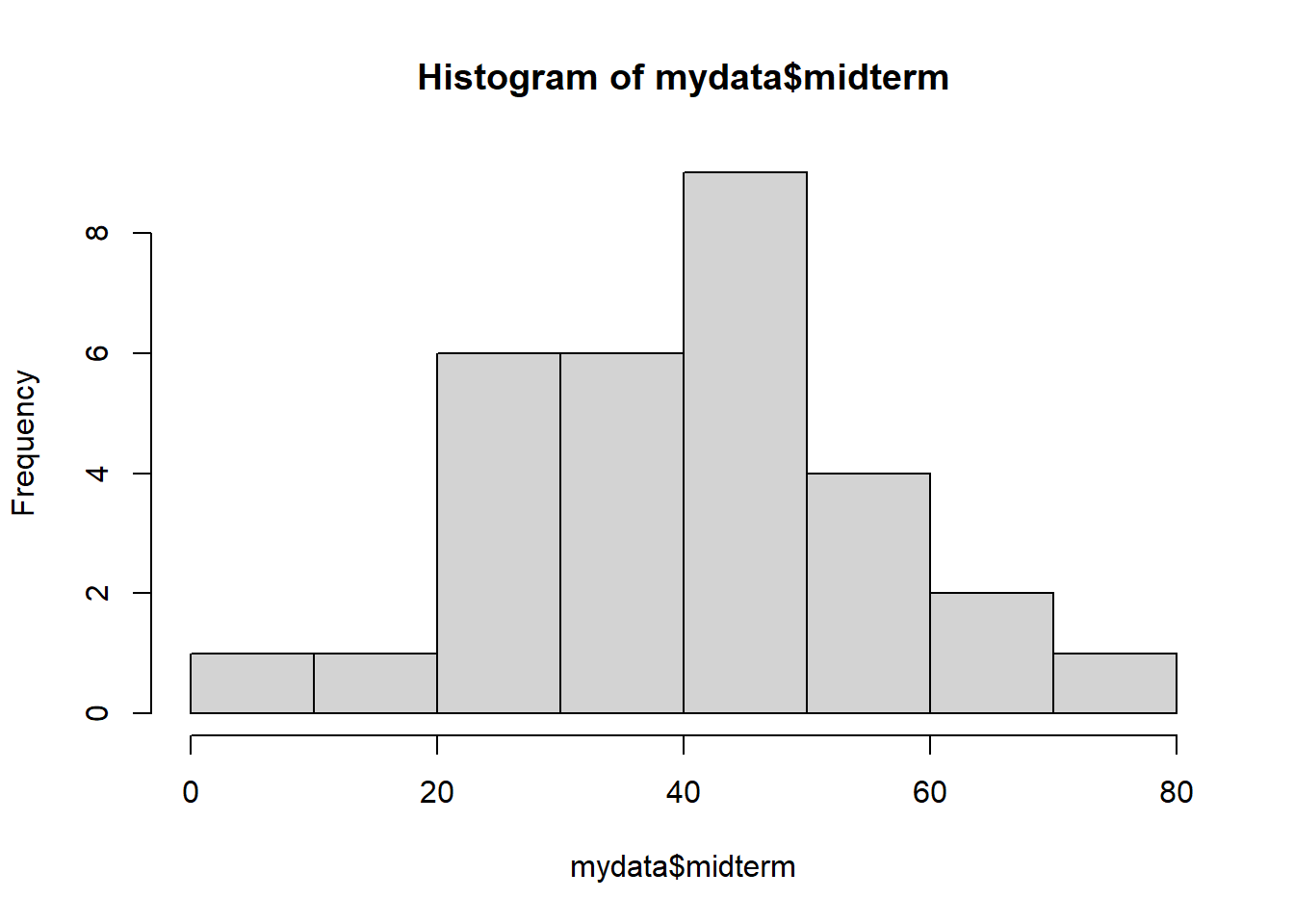
위의 그래프는 기본적으로 주어진 기본 단위 (기둥의 너비)가 10을 기준으로 하고 있습니다. 기본 단위를 breaks 옵션을 이용하여 우리가 원하는 방식으로 조정 할 수 있습니다.
hist(mydata$midterm, breaks= c(0:4)*20) # or
hist(mydata$midterm, breaks= c(0:20)*4)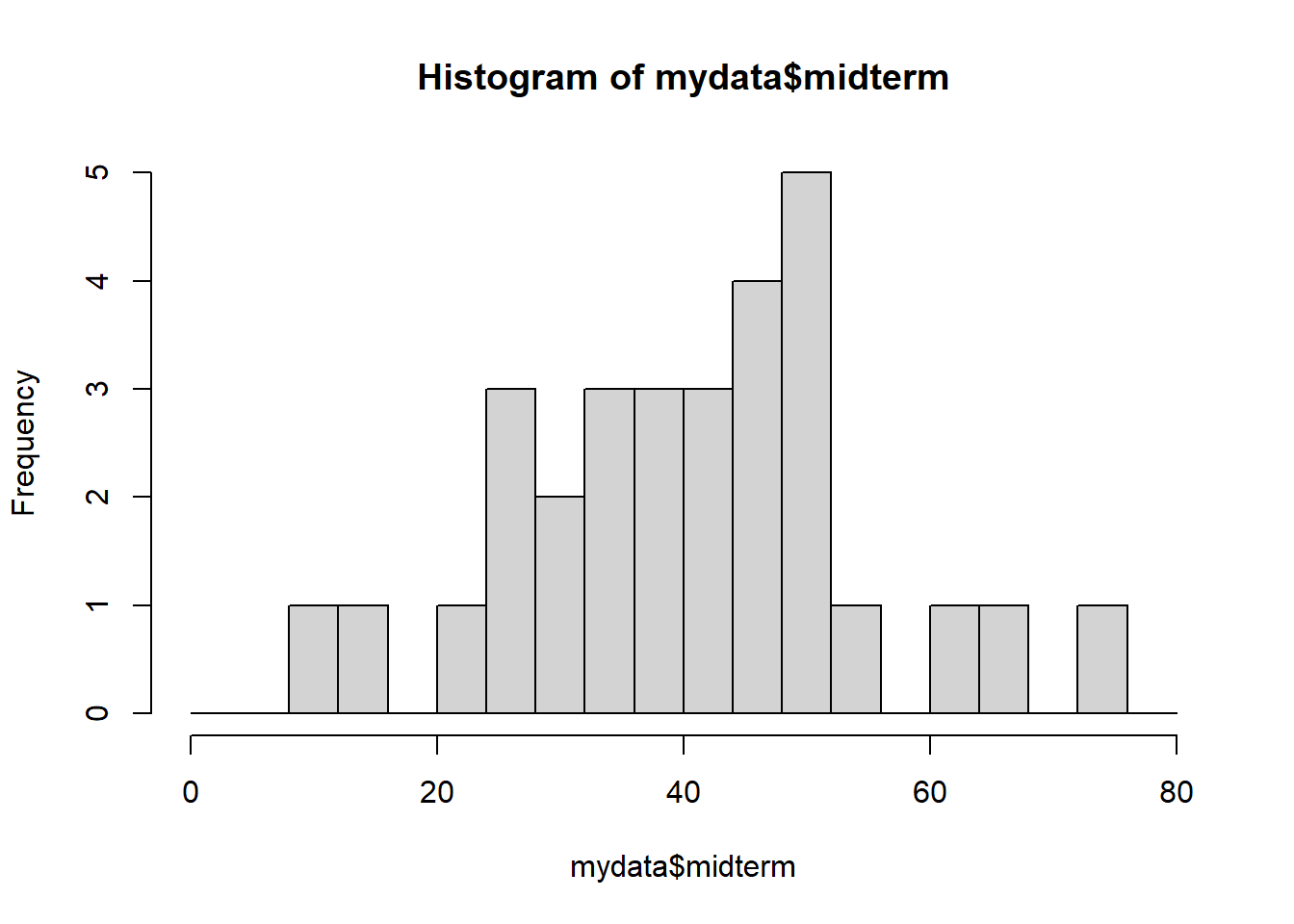
제목과 축 제목을 다음과 같이 설정할 수 있습니다.
hist(mydata$midterm, breaks= c(0:8)*10,
xlab = "중간고사 성적",
ylab = "빈도",
main = "중간고사 성적 분포")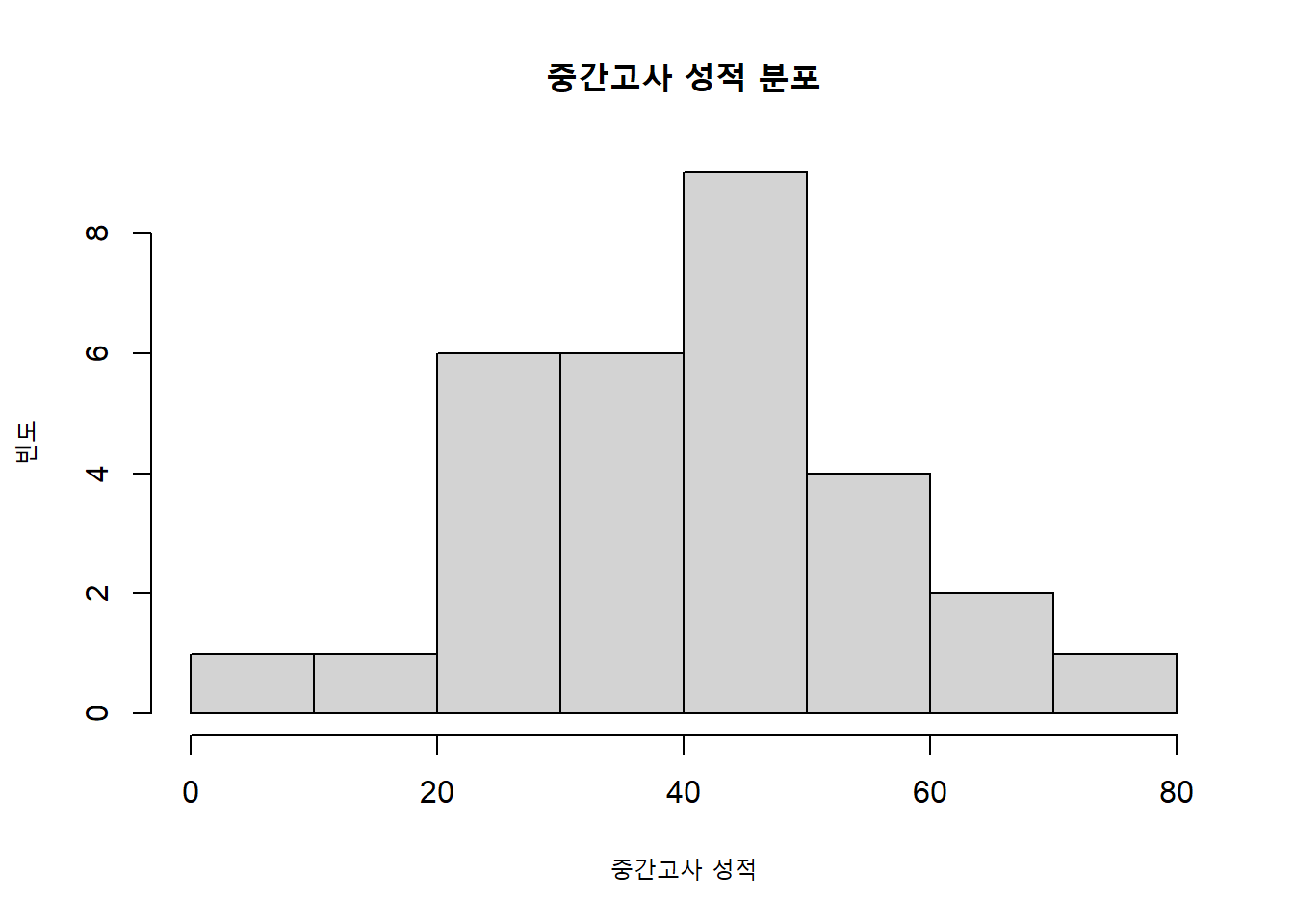
산점도 (Scatter plot)
산점도는두 개의 변수의 분포를 잘 살펴볼 수 있는 유용한 도구입니다.
plot(mydata$midterm, mydata$final,
xlab = "중간고사",
ylab = "기말고사",
main = "시험점수 산점도")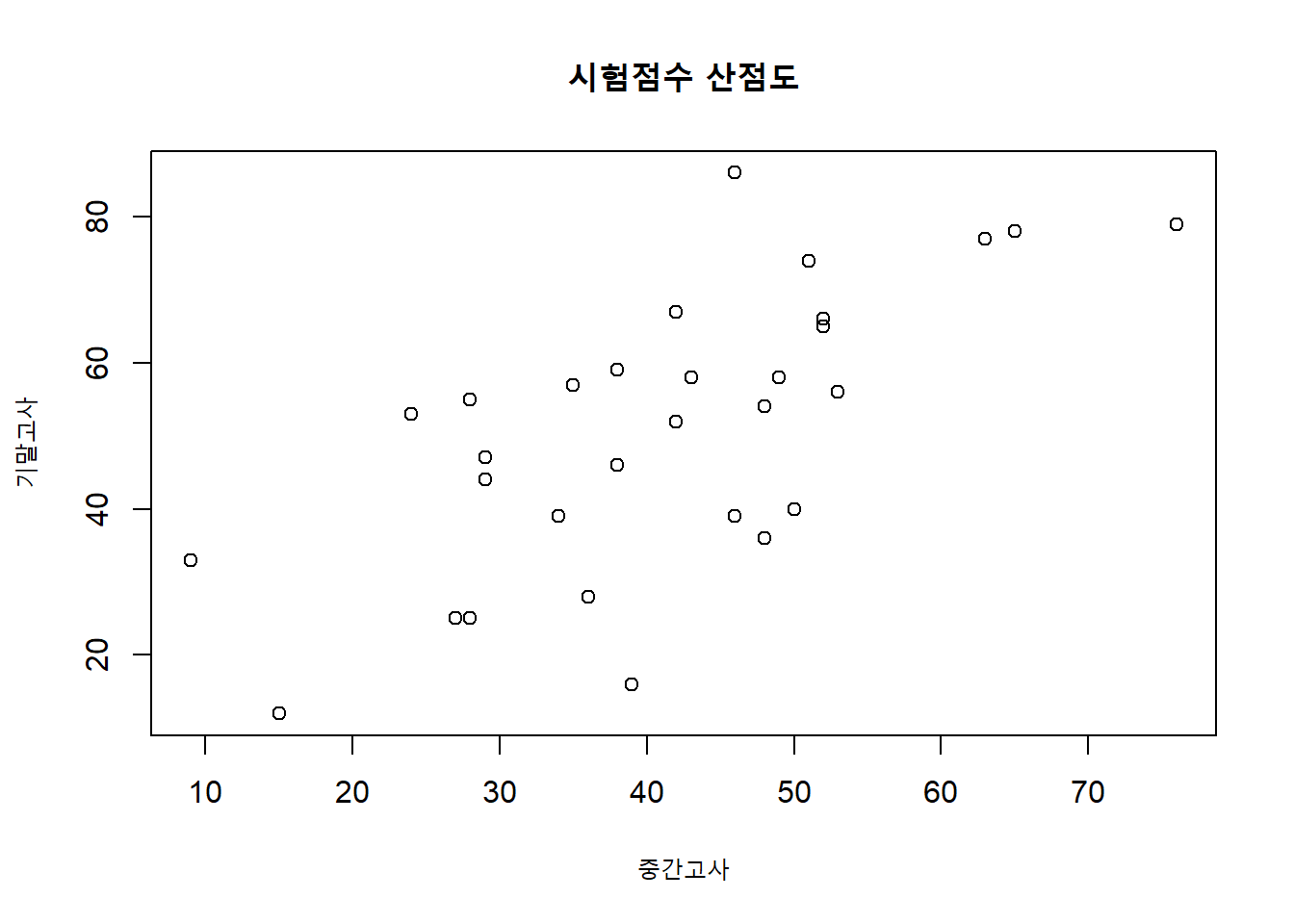
그래프를 그릴 때에는 항상 X축과 Y축의 비율이 똑같은지를 확인해야 합니다. 비율이 맞지 않을 경우 해석에 오류가 날 수 있습니다. 그래프의 비율을 다음과 같이 asp 옵션을 사용하여 맞출 수 있습니다.
plot(mydata$midterm, mydata$final, asp = 1,
xlab = "중간고사",
ylab = "기말고사",
main = "시험점수 산점도")
상자 그림 (Box plot)
박스 플롯은, 한글로는 상자 그림이라고 번역이 되어 있습니다, 주어진 변수의 분포를 잘 보여주는 직관적인 그래프입니다. R에서는 boxplot이라는 함수를 통하여 그려낼 수 있습니다.
boxplot(mydata$midterm,
main="중간고사 점수 분포",
xlab="점수",
horizontal = TRUE)
중간고사 점수 중 하나는 바꾸어 아웃라이어(outlier)를 만들어보도록 하자.
mydata$midterm[1] <- 100 # what does this mean?
boxplot(mydata$midterm,
main="중간고사 점수 분포",
xlab="점수",
horizontal = TRUE)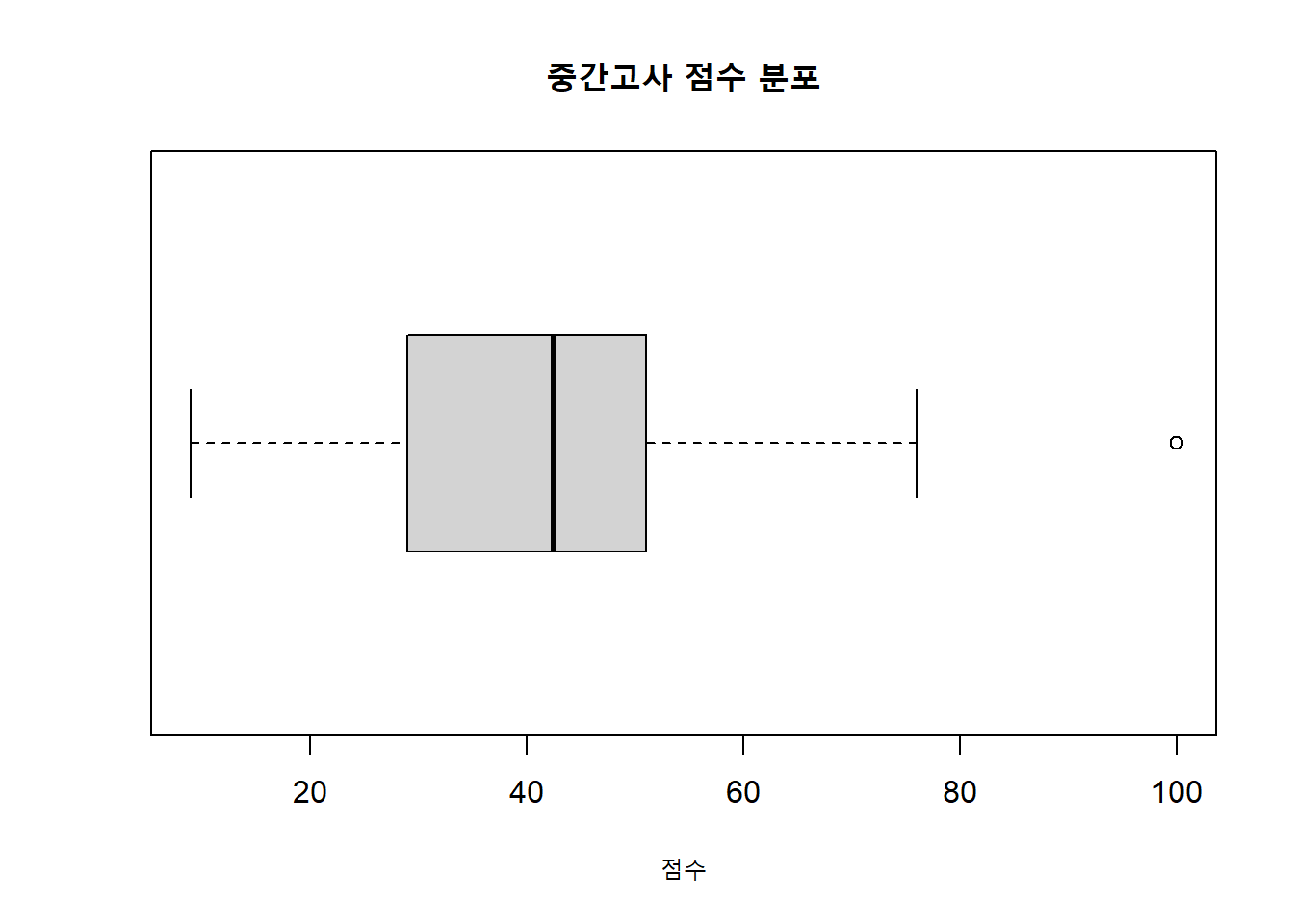
여러개의 상자그림을 한번에 그릴수도 있습니다.
boxplot(mydata$midterm, mydata$final,
main="시험 점수 분포도",
names = c("중간고사", "기말고사"),
xlab="점수",
ylab="시험",
horizontal = TRUE)
'R > RSTAT101' 카테고리의 다른 글
| [RSTAT101] 7강. R에서 회귀분석 실행하기 (2) | 2023.06.10 |
|---|---|
| [RSTAT101] 6강. 회귀직선의 의미와 구하는 방법 (0) | 2023.06.10 |
| [RSTAT101] 5강. 상관계수의 의미와 시각화 (0) | 2023.06.10 |
| [RSTAT101] 4강. 사용자 정의함수와 최빈값 (0) | 2023.06.10 |
| [RSTAT101] 3강. 평균과 중앙값, 분산과 IQR의 관계 이해하기 (1) | 2023.06.10 |




댓글