데이터를 시각화하는데 사용할 수 있는 많은 유형의 통계 그래프가 있지만, 가장 널리 사용되는 그래프는 다음과 같습니다.
- 선 그래프(Line graph): 선 그래프는 시간 경과에 따른 추세를 표시하거나 여러 변수를 비교하는 데 사용됩니다. 기온, 주가, 인구 증가와 같은 연속 변수에 대한 데이터를 표시하는 것은 일반적인 방법입니다.
- 막대 차트: 막대 차트는 여러 범주 또는 데이터 그룹을 비교하는 데 사용됩니다. 성별, 나이 또는 직업과 같은 범주형 변수의 데이터를 표시하는 데 사용할 수 있습니다.
- 히스토그램: 히스토그램은 연속형 변수의 분포를 표시하는 데 사용됩니다. 막대 차트와 비슷하지만 서로 다른 범위 또는 빈 내의 데이터 빈도를 표시하는 데 사용됩니다.
- 산점도: 산점도는 두 연속형 변수 사이의 관계를 표시하는 데 사용됩니다. 데이터에서 패턴과 상관 관계를 식별하는 데 사용할 수 있습니다.
- 상자 그림: 상자 그림 또는 상자 그림은 연속형 변수의 분포를 표시하는 데 사용됩니다. 데이터의 중위수, 사분위수 및 범위와 특이치가 표시됩니다.
- 그 외: 데이터의 유형과 전달하고자 하는 메시지에 따라 히트맵, 바이올린 플롯, 등고선도 등의 다른 유형의 그래프도 있습니다.

이번 블로그 포스팅에서는 위 그래프 종류를 ggplot2에서는 어떻게 그릴 수 있는지 알아보도록 하겠습니다.
선 그래프 (Line graph)
먼저 gapminder와 tidyverse가 없다면, 라이브러리를 설치합니다.
# install.packages("gapminder")
# install.packages("ggplot2")gapminder와 tidyverse 라이브러리를 불러오고, 인도의 gdpPercap
library(tidyverse)
library(gapminder)
# 특정 국가의 데이터를 필터링합니다
data_country <- filter(gapminder, country == "India")
# ggplot() 및 geom_line()을 사용하여 선 그래프를 만듭니다
ggplot(data_country, aes(year, gdpPercap, color = country)) +
geom_line() +
ggtitle("GDP per Capita for India") +
xlab("Year") +
ylab("GDP per Capita")+
theme_classic()
이 코드는 filter() 함수를 사용하여 인도의 갭마인더 데이터 세트를 필터링합니다. 그런 다음 수년간 인도의 1인당 GDP를 나타내는 선 그래프를 geom_line()를 사용하여 만들고 있습니다. 마지막으로 코드는 ggplot()을 사용하여 data_country 데이터 프레임의 year 및 gdpPercap 변수와 제목, x축 레이블 및 y축 레이블을 사용하여 선 그래프를 만듭니다. teme_classic() 함수는 그래프 스타일을 지정합니다.
geom_line에 사용되는 옵션들
geom_line() 함수는 선 그림의 모양과 스타일을 사용자 정의하는 데 사용할 수 있는 여러 인수를 사용합니다.
color: 선의 색상을 지정하는 데 사용됩니다.size: 선의 너비를 지정하는 데 사용됩니다.linetype: 선 유형(실선, 점선 등)을 지정하는 데 사용됩니다.linewidth: 선 굵기를 지정하는 데 사용됩니다.alpha: 선의 투명도를 지정하는 데 사용됩니다.group: 동일한 그림에서 선을 함께 그룹화하는 데 사용됩니다.show_guide: 입니다: 범례를 표시할지 여부를 지정하는 데 사용됩니다.na.rm: 결측값을 그림에서 제거할지 여부를 지정하는 데 사용됩니다.
위의 요소들을 적용하여 그래프를 바꿔보도록 합시다.
ggplot(data_country, aes(year, gdpPercap, color = country)) +
geom_line(
color = "blue",
linewidth = 2,
linetype = "dashed",
alpha = 0.5,
show.legend = TRUE,
na.rm = FALSE
) +
ggtitle("GDP per Capita for India") +
xlab("Year") +
ylab("GDP per Capita") +
theme_classic()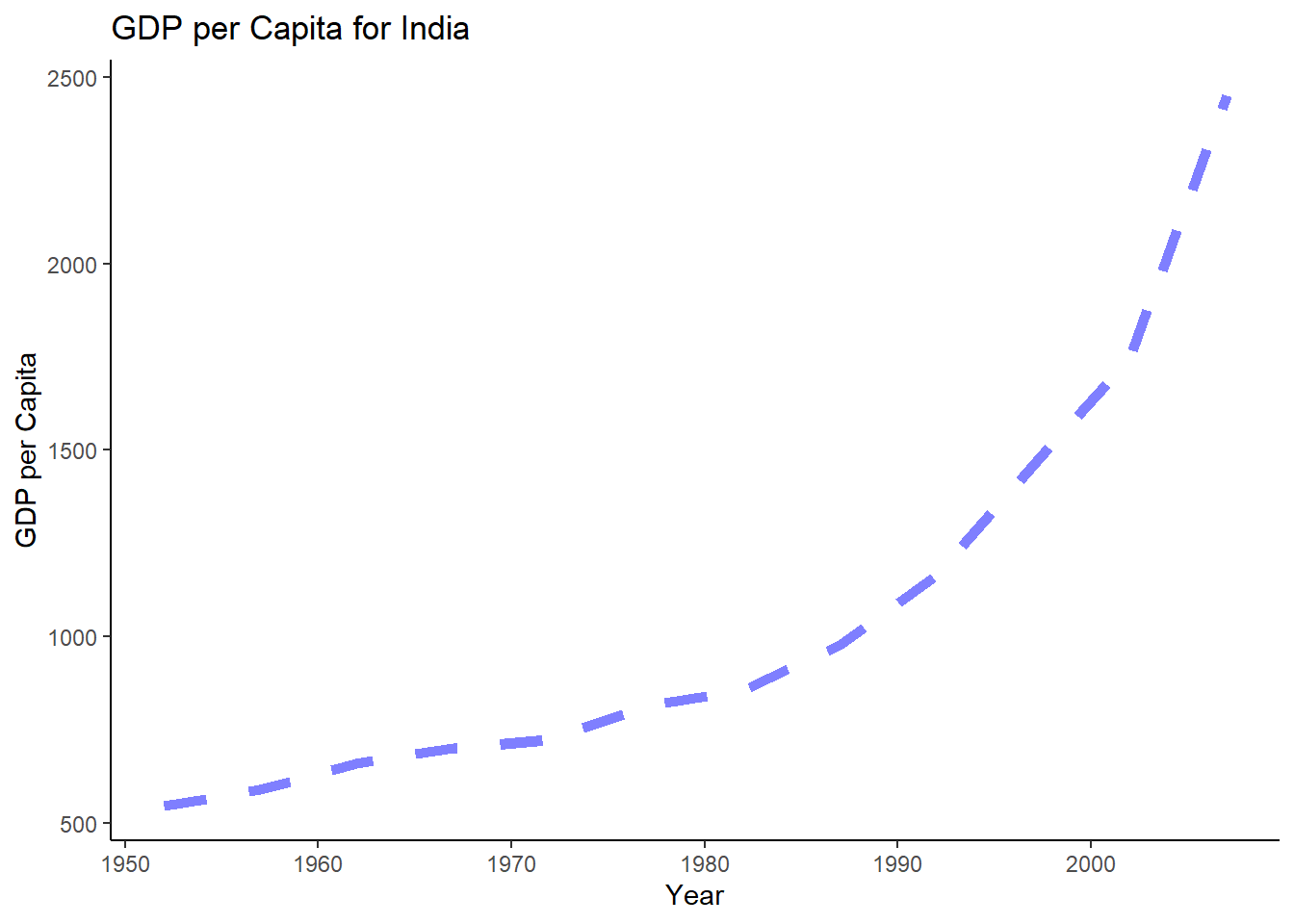
선 여러개 그리기
여러 나라들에 대한 선 그래프 그리는 방법입니다.
data_country2 <- filter(gapminder, country %in%
c("India", "China", "Brazil",
"Japan", "South Africa", "USA"))
ggplot(data_country2, aes(year, gdpPercap, color = country)) +
geom_line() +
ggtitle("GDP per Capita for Various Countries") +
xlab("Year") +
ylab("GDP per Capita")+
theme_classic()
이 코드는 %in% 연산자를 사용하여 6개국(인도, 중국, 브라질, 일본, 남아프리카 및 미국)의 데이터를 필터링하고 있습니다. 그런 다음 ggplot 함수를 사용하여 데이터를 시각화하는 선 그래프를 만들고, x축은 연도를 나타내고 y축은 1인당 GDP를 나타냅니다. 여기서 키 포인트는 country 변수를 color 요소에 묶어놨다는 것입니다. 같은 나라 gdp를 같은 색깔로 설정한 것이죠.
바 차트 (Bar chart) 그리기
아래 코드는 2007년 인도, 중국, 브라질, 일본, 남아프리카 및 미국의 기대 수명을 나타내는 막대 차트를 만들고 있습니다. 코드는 먼저 지정된 국가와 연도만 포함하도록 갭마인더 데이터 세트를 필터링 filter()한 다음 ggplot2의 geom_bar() 레이어를 사용하여 막대 차트를 생성합니다.
data_country3 <- gapminder %>%
filter(year == 2007,
country %in% c("India", "China", "Brazil", "Japan", "South Africa", "USA"))
# Step 2: Draw the bar chart
ggplot(data_country3, aes(x = country, y = lifeExp)) + geom_bar(stat = "identity") +
xlab("Country") + ylab("Life Expectancy") +
ggtitle("Life Expectancy for Selected Countries in 2007")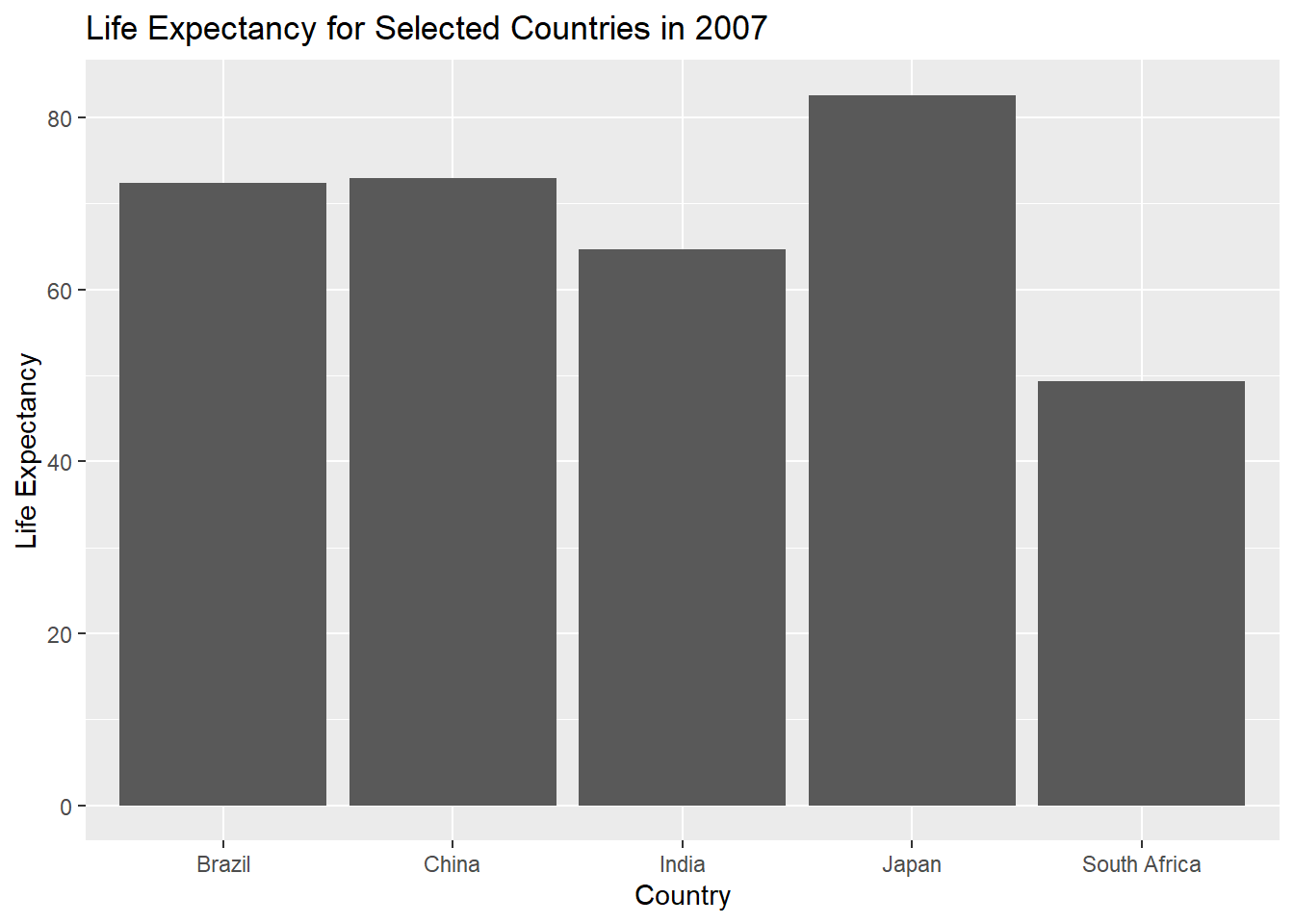
geom_bar()는 막대 차트를 생성하는 ggplot2 패키지의 함수입니다. 이 함수는 데이터 집합과 변수 매핑이라는 두 가지 인수가 필요합니다. stat 인수는 y축이 데이터 집합의 실제 값을 나타내도록 “identity”로 설정해 줍니다. 만약 y축 데이터가 벡터로 들어온 경우에는 “count”로 설정해줘야 합니다.
바 차트 막대 순서 변경하기
reorder() 함수는 국가의 기대 수명에 따라 순서를 변경하는 데 사용됩니다. 국가가 포함된 열과 기대 수명 값이 포함된 열을 입력으로 사용하고, 기대 수명 값(lifeExp)을 기준으로 새로운 순서로 국가를 출력합니다.
ggplot(data_country3,
aes(x = reorder(country, lifeExp), y = lifeExp)) +
geom_bar(stat = "identity") +
xlab("Country") + ylab("Life Expectancy") +
ggtitle("Life Expectancy for Selected Countries in 2007")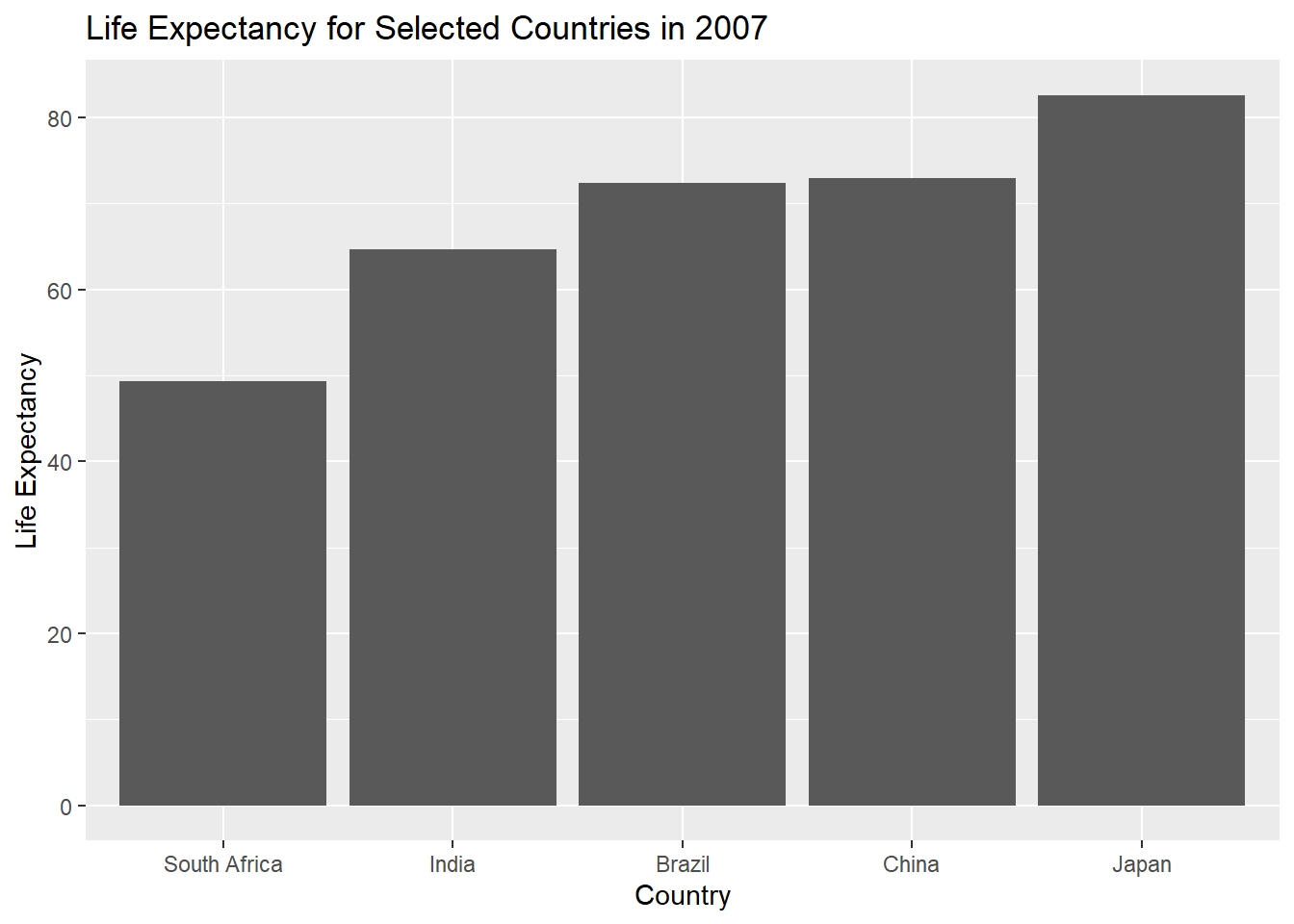
reorder() 함수의 옵션을 decreasing = TRUE로 설정하면 막대 정렬 순서를 뒤집어서 나타낼 수 있다.
ggplot(data_country3,
aes(x = reorder(country, lifeExp, decreasing = TRUE),
y = lifeExp)) +
geom_bar(stat = "identity") +
xlab("Country") + ylab("Life Expectancy") +
ggtitle("Life Expectancy for Selected Countries in 2007")
히스토그램 (Histogram) 그리기
갭마인더 데이터에서 1992년의 인구에 대한 기본 히스토그램을 생성하려면 다음 코드를 사용할 수 있습니다.
# 1992년의 관측치만 포함하도록 데이터를 필터링합니다
gapminder_1992 <- gapminder %>%
filter(year == 1992)
# 1992년에 대한 인구 히스토그램을 만듭니다.
ggplot(data = gapminder_1992, aes(x = pop)) +
geom_histogram() +
labs(title = "Histogram of Population in Year 1992",
x = "Population",
y = "Frequency")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
geom_histogram() 함수의 binwidth 인수는 히스토그램에서 빈의 너비를 제어합니다. 각 빈에서 함께 그룹화되는 값의 범위를 결정합니다. binwidth 인수에 사용되는 값은 히스토그램의 모양에 큰 영향을 미칠 수 있으므로 적절한 값을 선택하는 것이 중요합니다.
상자너비 선택하기
통계에서 히스토그램의 빈 너비를 결정하는 방법에는 여러 가지가 있습니다. 가장 일반적으로 사용되는 방법은 다음과 같습니다:
- 스콧의 법칙(The Scott’s rule): 스콧의 규칙에 따르면 최적의 빈 너비는 \(h = 3.5\sigma/n^{1/3}\)로 주어지며, 여기서 \(\sigma\)는 표준 편차이고 \(n\)은 데이터 점의 개수입니다. 이 규칙은 최적의 빈 너비가 데이터의 표준 편차에 비례해야 한다는 개념을 기반으로 합니다.
- 프리드먼-다이아코니스 규칙(The Freedman-Diaconis rule): Freedman-Diaconis 규칙은 표준 편차 대신 사분위간 범위(IQR)를 기반으로 하는 Scott의 규칙에 대한 대안입니다. 최적의 빈 너비는 \(h = 2 IQR/n^(1/3)\)에 의해 제공됩니다. IQR은 표준 편차보다 특이치에 더 강한 데이터의 산포에 대한 측도입니다.
- 라이스의 법칙(The Rice rule): 라이스 규칙은 스콧 규칙과 유사하지만 데이터 점의 수 대신 표본 크기를 사용합니다. 최적의 빈 폭은 \(h = 2 * (n * µ^2 / 3)^(1/3)\)에 의해 주어집니다
- 제곱근 법칙(The Square-root choice): 제곱근 선택은 빈 너비를 결정하는 가장 간단한 방법 중 하나입니다. 최적의 빈 너비는 \(h = \sqrt{n}\)로 주어지며, 여기서 \(n\)은 데이터 점의 개수입니다.
- 스터지스의 법칙(The Sturges’ Rule): 스터지스 규칙은 히스토그램의 빈 수를 결정하기 위한 간단한 규칙입니다. 최적의 빈 수는 \(k = log2(n) + 1\)로 주어지며, 여기서 \(n\)은 데이터 점의 개수입니다.
이 밖에 시마자키 및 시노모토(Shimazaki and Shinomoto (SS) method) 방법이 있는데, 데이터의 분포와 데이터 점의 수를 고려하는 더 복잡한 알고리즘을 사용합니다. 이 방법은 빈 너비를 결정하는 방법 중 가장 정확한 것으로 간주됩니다만, 이 포스팅에서는 생략하도록 하겠습니다. 각각의 방법은 서로 다른 가정을 기반으로 하며, 서로 다른 장점과 단점이 있습니다.
실무에서는 히스토그램의 상자 너비를 결정하는 가장 일반적인 방법은 제곱근 선택 방법입니다. 이 방법은 간단하고 구현하기 쉬우며 데이터 분포를 시각적으로 잘 표현합니다.
gapminder_1992$pop |> head()## [1] 16317921 3326498 26298373 8735988 33958947 17481977gapminder_1992$pop |> range()## [1] 125911 1164970000sqrt(length(gapminder_1992$pop))## [1] 11.91638그러나 위 코드에서 보다시피 현재 데이터에 제곱근 방식을 적용하는 것은 너무 작은 상자 너비를 사용하게 하므로, Scott의 규칙과 Freedman-Diaconis 규칙 적용해보도록 하자.
- Scott’s rule 적용하여 상자 너비 계산
h_scott <- 3.5 * sd(gapminder_1992$pop) / length(gapminder_1992$pop)^(1/3)
ggplot(data = gapminder_1992, aes(x = pop)) +
geom_histogram(binwidth = h_scott) +
labs(title = "Histogram of Population in Year 1992",
x = "Population",
y = "Frequency")
- Freedman-Diaconis rule 적용하여 상자 너비 계산
h_fd <- 2 * IQR(gapminder_1992$pop) / length(gapminder_1992$pop)^(1/3)
ggplot(data = gapminder_1992, aes(x = pop)) +
geom_histogram(binwidth = h_fd) +
labs(title = "Histogram of Population in Year 1992",
x = "Population",
y = "Frequency")
h_fd 변수가 좀 더 좋아보여 채택하도록 합니다. 주어진 히스토그램을 보았을때, 오른쪽으로 치우친 분포를 따릅니다. 이 경우 몰려있는 부분의 데이터를 잘 볼 수 없기 때문에, log를 취해서 숨어있는 패턴을 탐색해도 좋습니다.
ggplot(data = gapminder_1992, aes(x = log(pop))) +
geom_histogram() +
labs(title = "Histogram of Population in Year 1992 (Log scale)",
x = "Log(Population)",
y = "Frequency")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.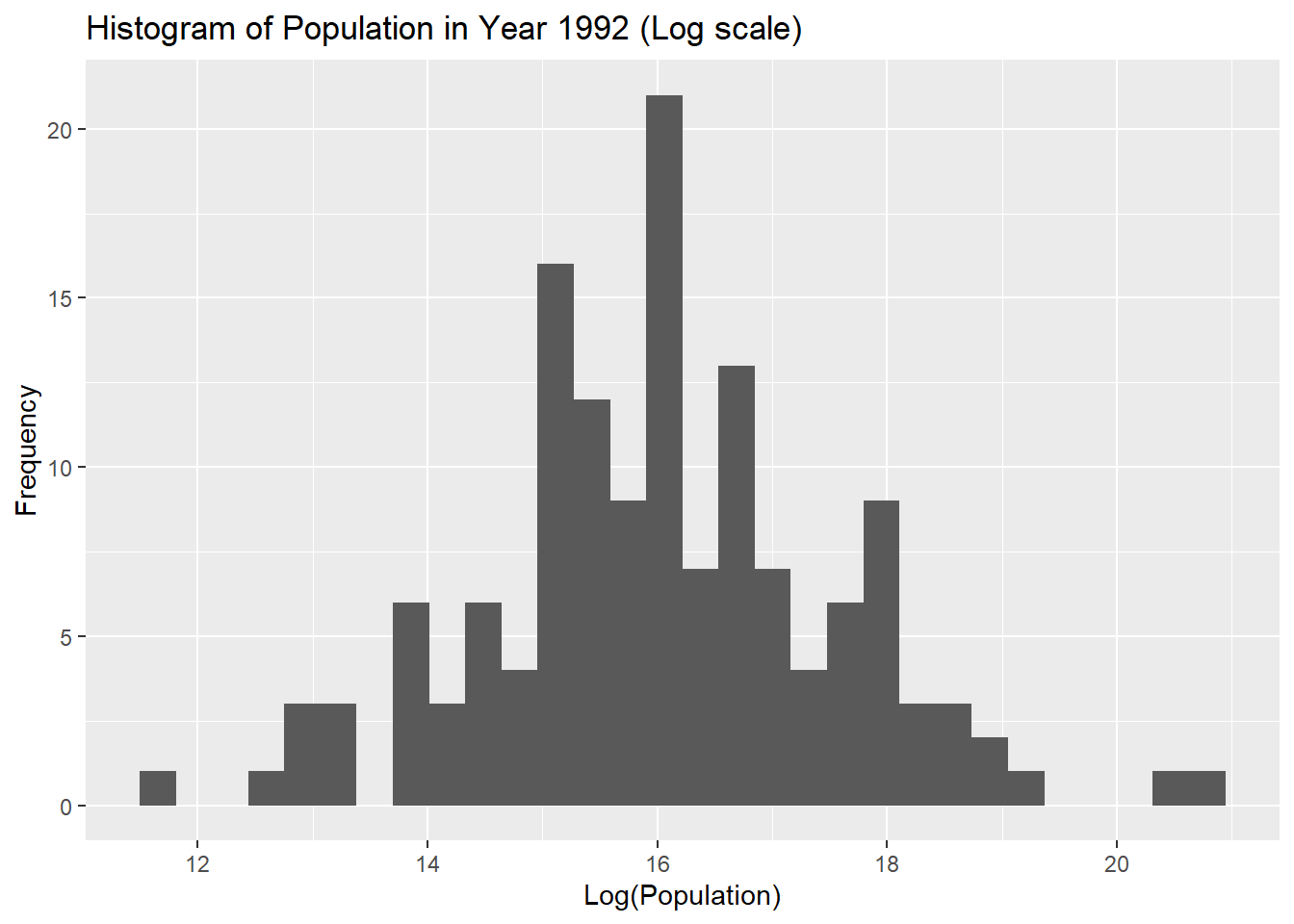
인구 분포에 로그를 취하니 종 모양 분포를 따르는 것을 확인할 수 있습니다. 이렇게 변환 된 분포는 나라를 그룹별 구분하거나, 분석할 때 좀 더 편리합니다.
두 개 년도 비교하기
1992년과 2002년의 인구데이터를 로그를 취하고, 히스토그램을 그려 비교해 보겠습니다.
# 1992년 및 2002년의 관측치만 포함하도록 데이터를 필터링합니다.
gapminder_1992_2002 <- gapminder %>%
filter(year %in% c(1992, 2002))
# 각 연도에 대한 인구수의 로그 히스토그램을 만듭니다.
gapminder_1992_2002 %>%
ggplot(aes(x = log(pop), fill = factor(year))) +
geom_histogram(binwidth = 0.1) +
facet_wrap( ~ year, ncol = 1) +
scale_x_continuous(breaks = seq(3, 8, by = 0.5)) +
scale_fill_manual(values = c("#0073C2FF", "#ED1C24FF")) +
labs(title = "Histogram of log(Population) by Year 1992 vs. 2002",
x = "Log(Population)",
y = "Frequency",
fill = "Year") +
theme_minimal() +
theme(legend.position = "bottom")
코드는 갭마인더 데이터를 사용하여 1992년과 2002년의 인구수에 로그 히스토그램을 만듭니다. gapminder_1992_2002 변수는 filter() 함수를 사용하여 year 값을 기준으로 1992년과 2002년의 관측치만 포함하도록 gapminder 데이터를 필터링합니다.
facet_wrap(~year, ncol=1) 함수는 연도별로 데이터를 그룹화하고, 그래프 배치를 1개 열로 즉, 단일 열에 대해 ncol = 1을 사용하여, 각 연도에 대한 별도의 히스토그램을 만듭니다. 또한, 다음 설정을 통해서 그래프를 예쁘게 변형하였습니다.
scale_x_continuous(breaks = seq(3, 8, by = 0.5)): x축 눈금 정의scale_fill_manual(values = c("#0073C2FF", "#ED1C24FF")): 막대 색상 설정labs()함수는 제목, x축, y축 및 채우기 범례에 레이블을 제공theme_minimal(): 전체 테마를 변경theme(legend.position = "bottom"): 범례의 위치를 변경
산점도 (Scatter plot) 그리기
데이터를 사용하여 산점도를 그리려면 다음 코드를 사용할 수 있습니다.
gapminder %>%
ggplot(aes(
x = gdpPercap,
y = lifeExp,
color = continent,
size = pop
)) +
geom_point()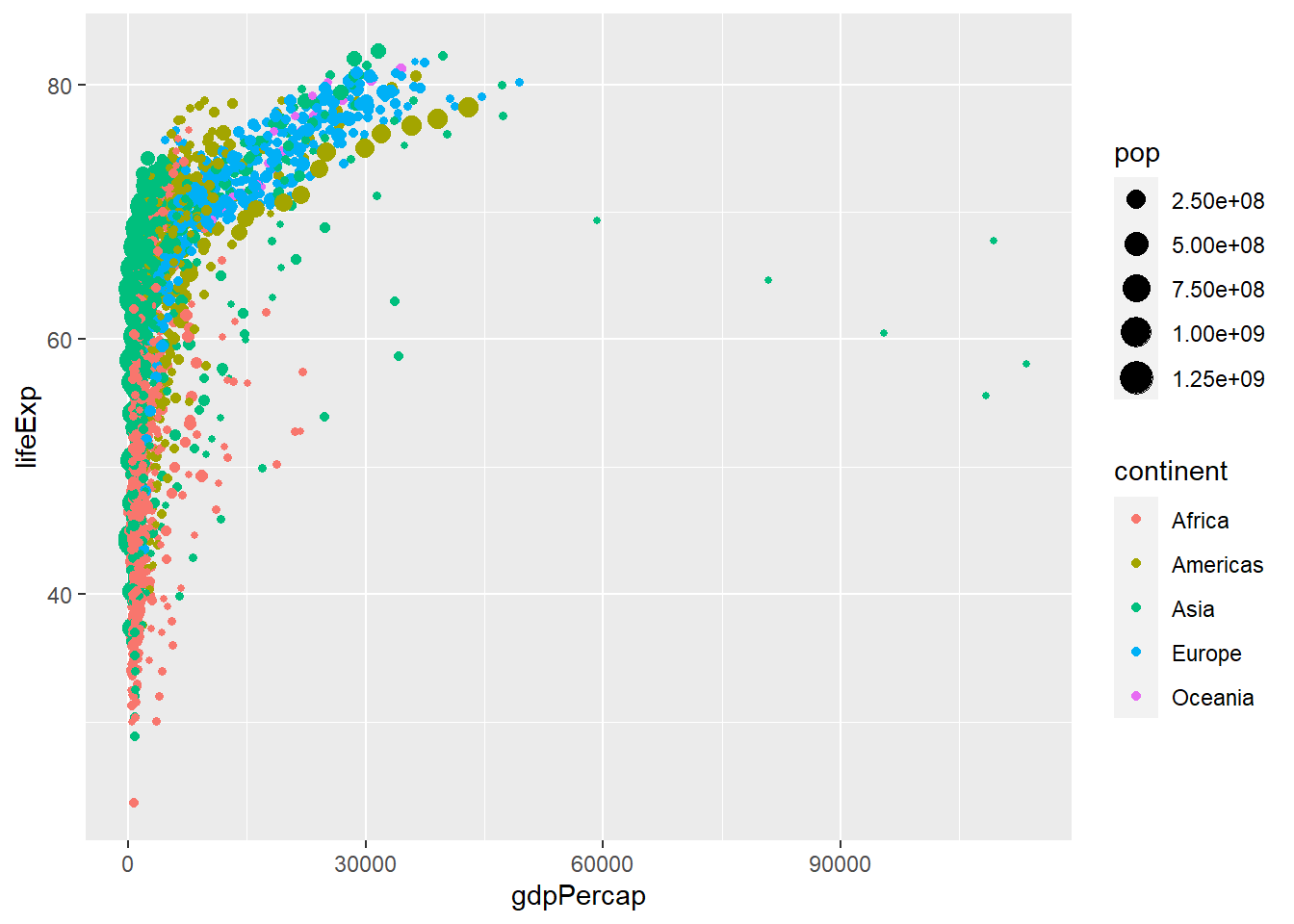
aes() 함수는 산점도에 대한 x 및 y 변수(이 경우 gdpPercap 및 lifeExp)를 지정하는 데 사용되며, 색상 변수는 데이터를 대륙별로 그룹화하는 데 사용됩니다. geom_point() 함수는 산점도를 만드는 데 사용됩니다. size는 점의 크기를 pop 변수의 정보를 반영하도록 사용됩니다.
gapminder %>%
ggplot(aes(
x = gdpPercap,
y = lifeExp,
color = continent,
size = pop
)) +
geom_point(alpha = I(0.5)) +
scale_color_manual(values =
c("blue", "red", "green", "yellow", "pink")) +
scale_size(range = c(1, 8)) +
guides(color = guide_legend(title = "Continent"),
size = guide_legend(title = "Population")) +
theme(legend.position = "bottom", legend.box="vertical")
alpha = I(0.5) 부분은 점들이 너무 많이 겹치는 현상을 해소하기 위해서 채택한 것이며, I() 함수는 0.5라는 값을 그대로 적용할 때 사용되는 함수이다. 같은 색깔이 같은 대률을 나타내고, 각 색깔들이 우상향하는 패턴을 보이는 것을 볼 때 모든 대륙에서 GDP가 증가할 수록 기대수명이 증가하는 추세를 보이는 것을 알 수 있습니다.
theme() 함수 안에 legend.box="vertical" 부분은 범례를 두 줄로 만들기 위한 설정 부분입니다.
특정 년도 기준 그리기
특정 년도 (1992년, 2002년)를 뽑아서, 같은 시기의 각 나타별 기대수명과 GDP를 그린 것이다.
gapminder_1992_2002 <- gapminder %>%
filter(year %in% c(1992, 2002))
gapminder_1992_2002 %>%
ggplot(aes(
x = gdpPercap,
y = lifeExp,
color = continent,
size = pop
)) +
geom_point(alpha = I(0.5)) +
facet_wrap( ~ year, ncol = 1) +
scale_color_manual(values = c("blue", "red", "green", "yellow", "pink")) +
scale_size(range = c(1, 8)) +
labs(title = "G.D.P. vs. Life Expectancy by Year",
x = "Gross Domestic Product per Capita.",
y = "Life Expectancy") +
theme_minimal() +
guides(color = guide_legend(title = "Continent"),
size = guide_legend(title = "Population")) +
theme(legend.position = "bottom",
legend.box="vertical")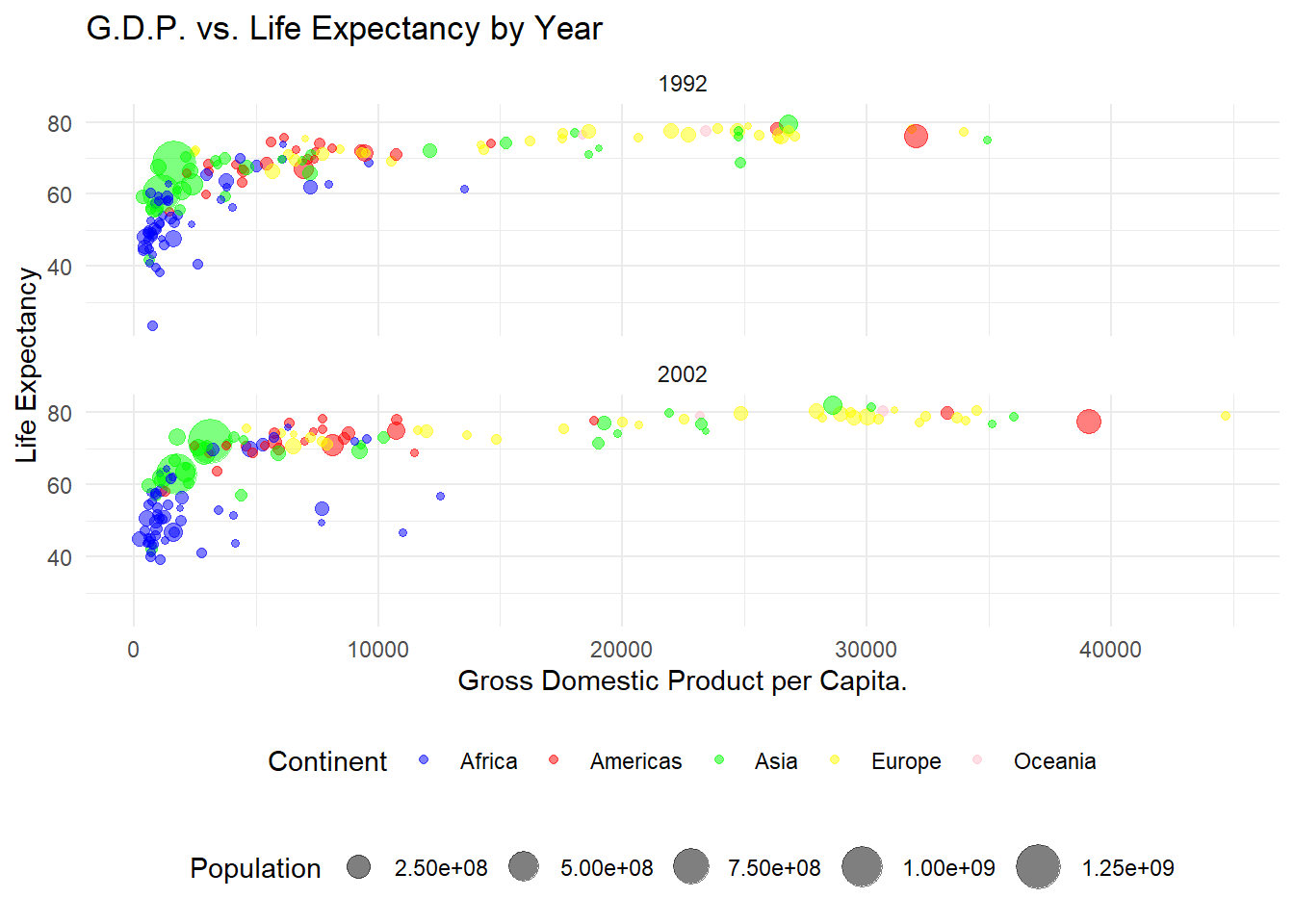
그래프를 보면 1992년과 2002년 기대수명 (y 축) 측면에서는 거의 같은 분포를 띄고 있는 것을 알 수 있다. 반면, GDP (x 축) 측면에서는 나라별 거리가 증가 한 것을 알 수 있는데, 이는 1990년대 이후 나라별 기대수명 격차보다는 GDP 격차가 더 벌어지고 있는 추세라는 것을 알 수 있다.
특정 데이터 표시하기
ggrepel 패키지의 gum_label_text 함수를 사용하여 산점도의 점에 레이블을 지정할 수 있습니다. geom_label_repel() 함수는 반발 알고리즘을 사용하여 레이블이 겹치지 않도록 하여 산점도의 점 레이블링에 유용합니다.
다음은 geom_label_repel()을 사용하여 1992년과 2002년 모두에서 기대 수명이 가장 높은 상위 5개국에 레이블을 지정하는 방법에 대한 예입니다.
library(ggrepel)
gapminder_1992_2002 <- gapminder %>%
filter(year %in% c(1992, 2002))
gapminder_1992_2002 %>%
ggplot(aes(
x = gdpPercap,
y = lifeExp,
color = continent,
size = pop
)) +
geom_point(alpha = I(0.5)) +
geom_label_repel(
data = gapminder %>% filter(year == 1992) %>%
arrange(desc(lifeExp)) %>% top_n(5, lifeExp),
aes(label = country),
direction = "both",
segment.size = 0.2,
color = "black",
size = I(3)
) +
geom_label_repel(
data = gapminder %>% filter(year == 2002) %>%
arrange(desc(lifeExp)) %>% top_n(5, lifeExp),
aes(label = country),
direction = "both",
segment.size = 0.2,
color = "black",
size = I(3)
) +
facet_wrap(~ year, ncol = 1) +
scale_color_manual(values = c("blue", "red", "green", "yellow", "pink")) +
scale_size(range = c(1, 8)) +
labs(title = "G.D.P. vs. Life Expectancy by Year",
x = "Gross Domestic Product per Capita.",
y = "Life Expectancy") +
theme_minimal() +
guides(color = guide_legend(title = "Continent"),
size = guide_legend(title = "Population")) +
theme(legend.position = "bottom",
legend.box="vertical")
레이블의 방향을 제어하기 위해 방향 direction = "both"를 추가했습니다. 즉, 레이블이 수평, 혹은 수직 공간을 활용하여 겹치지 않게 표시됩니다. 또한 레이블과 점 사이의 거리를 제어하기 위해 segment.size = 0.2를 추가했습니다.
상자그림 그리기
상자 그림 또는 상자 그림은 데이터의 중위수, 사분위수 및 범위를 표시하여 데이터 집합의 분포를 시각화하는 방법입니다. 다음은 R의 갭마인더 패키지에 있는 갭마인더 데이터를 사용하여 단정한 항 스타일로 상자 그림을 만드는 방법에 대한 예제입니다.
gapminder %>%
ggplot(aes(x = year, y = lifeExp, group = year)) +
geom_boxplot() +
theme_classic()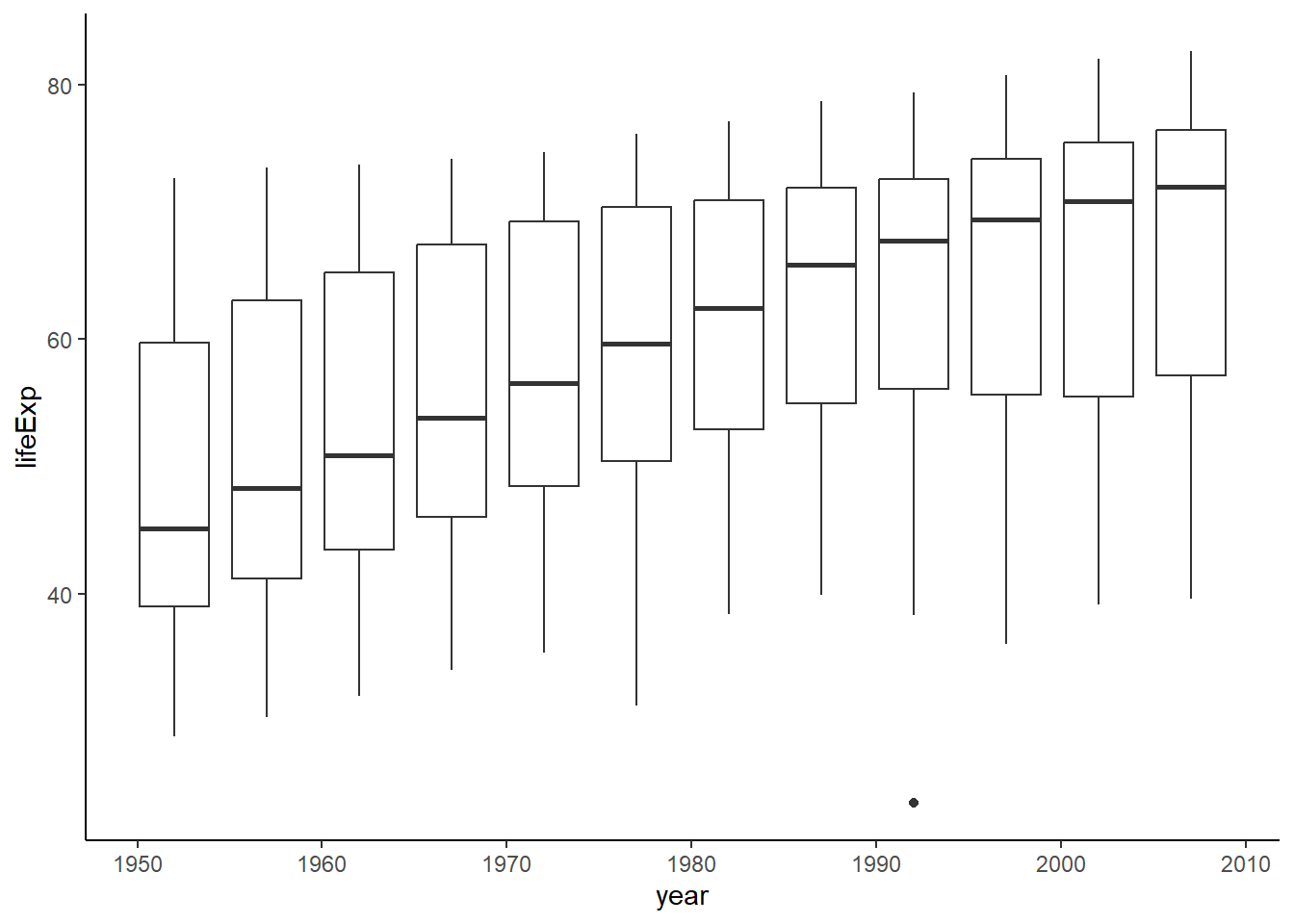
위의 그림은 년도가 증가하면서 기대수명의 중앙값이 증가하는 경향성을 보이는 것을 볼 수 있습니다. 2002년에 대응하는 데이터만 선택하여, 각 대륙별 기대수명을 구해보도록 하겠습니다.
gapminder_2002 <- gapminder %>% filter(year == 2002)
gapminder_2002 %>%
ggplot(aes(x = continent,
y = lifeExp,
group = continent)) +
geom_boxplot() +
theme_classic()
그래프를 보면 상대적으로 아프리카 대륙의 기대수명이 다른 대륙에 비하여 2002년도에도 상당히 떨어지는 것을 알 수 있습니다. 상자그림의 상자 가운데 가로선인 중앙값을 기준으로 상자들을 정렬하고 싶습니다.
기대수명 중앙값 기준으로 정렬하기
기대수명의 중위수 lifeExp를 기준으로 상자 그림을 정렬해봅시다. 먼저 각 대륙의 중위수 lifeExp를 계산한 다음, 해당 중위수를 기준으로 데이터 프레임을 정렬하고 마지막으로 정렬된 대륙을 상자 그림의 x축에 매핑할 수 있습니다.
gapminder_2002 %>%
group_by(continent) %>%
summarize(median_lifeExp = median(lifeExp)) %>%
arrange(median_lifeExp) %>%
right_join(gapminder_2002, by = "continent") %>%
ggplot(aes(x = reorder(continent, median_lifeExp),
y = lifeExp,
group = continent)) +
geom_boxplot() +
theme_classic()
위 코드를 살펴봅시다.
group_by(continent)를 사용하여 대륙별로 그룹을 만든 후,summarize(median_lifeExp = median(lifeExp))을 사용하여 각 대륙의 중위수lifeExp를 계산합니다.arrange(median_lifeExp)을 사용하여 중위수_lifeExp를 기준으로 데이터 프레임을 정렬합니다.right_join(gapminder_2002, by = "continent")를 사용하여 정렬된 데이터 프레임을 원본 데이터에 추가합니다.reorder(continent, median_lifeExp)함수를 사용하여 정렬된 대륙을 상자 그림의 x축에 매핑합니다.
예쁘게 만들기
앞에서 그린 상자그림은 조금 심심하므로 예쁘게 만들어 줍시다.
gapminder_2002 %>%
group_by(continent) %>%
summarize(median_lifeExp = median(lifeExp)) %>%
arrange(median_lifeExp) %>%
right_join(gapminder_2002, by = "continent") %>%
ggplot(aes(
x = reorder(continent, median_lifeExp),
y = lifeExp,
group = continent
)) +
geom_boxplot(fill = "lightblue", color = "black") +
labs(title = "대륙별 기대수명 중앙값 (2002년)",
x = "대륙",
y = "기대수명 (년)") +
theme_minimal() +
theme(
panel.grid.major = element_line(color = "gray", linetype = "dotted"),
axis.text.x = element_text(angle = 45, hjust = 1)
)
위의 코드에서 주목해 봐야한 부분들을 짚어보겠습니다.
- 먼저
theme_minimal()를 사용하여 깨끗한 그래프를 만들어줍니다. theme()함수를 사용하여 그래프 배경 줄과 가로 축 제목을 변경해줍니다.panel.grid.major = element_line(color = "gray", linetype = "dotted": 배경 줄 회색 점선으로 변경axis.text.x = element_text(angle = 45, hjust = 1)): 가로축 제목을 높이 조정 및 45도 꺾어줌
'R' 카테고리의 다른 글
| R 프로그래밍 apply() 함수 - 당신의 코드를 짧고 간결하게 (0) | 2023.04.05 |
|---|---|
| R에서 Python 연결 시 에러 해결법 (0) | 2023.03.05 |
| R 그래프 그리는 법 - plot() 함수 옵션과 예제 (0) | 2023.01.28 |
| Rmd 파일 저장할 때 knit하기 저장용 (0) | 2022.01.26 |
| gganimate 패키지로 신년 메세지 동영상만들기 (1) | 2022.01.02 |



댓글