이번 장에서는 torch 및 다른 딥러닝 라이브러리의 근본을 이루는 기능인 미분 자동 추적 기능에 대하여 알아보도록 하자. 예를 들어 설명하는 것을 좋아하므로, 이번 챕터에 쓸 예제 함수를 먼저 정의하자.
예제 함수
\(n\)개의 데이터 \(x_1, ..., x_n\)이 주어졌다고 할 때, 우리는 다음의 함수 \(f\)를 정의 할 수 있다.
\[ f(\mu) = \frac{1}{n}\sum_{i=1}^{n}(x_i - \mu)^2 \]
위의 함수는 다음과 같이 해석해 볼 수 있다. \(x\) 데이터에 담겨있는 정보를 단 하나의 지표 \(\mu\)로 압축해서 나타낸다고 할 때, 함수 \(f\)는 각 관찰값에 대한 오차들, \(x_i - \mu\),의 제곱의 평균을 나타낸다.
통계학에서는 나름 유명한 함수인데, 왜냐하면 위의 함숫값을 최소화시키는 \(\mu\)를 찾게되면 표본 평균(\(\bar {x}\)) 나오기 때문이다. 오늘은 이 함수를 통하여 torch의 자동 미분 기능에 대하여 알아보고자 한다.
데이터 생성
torch패키지를 불러 임의로 난수를 발생시킨 후, 텐서 x에 집어넣도록 하자.
library(tidyverse)
library(torch)
# set seed in torch
torch_manual_seed(2021)
x_tensor <- torch_rand(7) * 10
x_tensor## torch_tensor
## 1.3044
## 5.1339
## 7.4256
## 7.1589
## 5.7047
## 1.6527
## 0.4431
## [ CPUFloatType{7} ]위의 코드에서 쓰인 함수 두 개를 알아보자.
torch_manual_seed():base패키지의set.seed()함수와 같다. 시뮬레이션할 때 시드를 고정하는 역할을 한다.torch_rand():base패키지에서runif()함수와 같다. 균등분포(Uniform distribution) 분포에서 원하는 개수만큼 표본을 뽑는다.
함수 만들기 및 오차 그래프
앞에서 살펴본 함수 \(f\)는 모수(\(\mu\))를 입력값으로 하는 함수이므로, 다음과 같이 함수를 정의 할 수 있다.
f <- function(mu, x){
mean((x - mu)^2)
}
f(2, x_tensor)## torch_tensor
## 11.8036
## [ CPUFloatType{} ]위에서 알 수 있듯, \(\mu\) 값이 2인 경우에 대한 오차들의 제곱의 평균값은 11.8036이다. 여러 \(\mu\) 값에 대하여 f 함수의 값을 구해보자.
mu_vec <- seq(0, 10, by = 0.02)
result <- map_dbl(mu_vec, ~as.numeric(f(mu = .x,
x = x_tensor)))
head(result)## [1] 24.27407 24.10977 23.94626 23.78356 23.62166 23.46055위의 두 정보를 이용해서 f의 모양이 어떻게 생겼는지 그려보면 다음과 같이 2차원 곡선을 띄고 있다는 것을 알 수 있다.
library(latex2exp)
library(ggthemes)
theme_set(theme_igray())
plot_data <- tibble(x = mu_vec,
y = result)
p <- ggplot(data = plot_data, aes(x = x, y = y)) +
geom_line() +
labs(x = TeX("$\\mu$"),
y = TeX("$f(\\mu;x)$"))
p
우리의 목표는 바로 저 곡선을 최소로 만드는 \(\mu\) 값이 무엇인지 찾아내는 것이다. 이 최소값을 찾기 위해서는 경사 하강법 같은 방법을 사용해야 하는데, 이러한 알고리즘들의 핵심은 바로 주어진 \(\mu\)값에 대응하는 기울기 값을 구하는 것이다.
우리가 임의로 정한 시작점 \(\mu_i\)에서 목표인 \(\mu_{*}\)까지 찾아가기 위해서 경사 하강법을 통하면 다음의 과정을 \(\mu\)값이 수렴할 때까지 반복하면 된다.
\[ {\displaystyle \mathbf {\mu} _{i+1}=\mathbf {\mu} _{i}-\gamma _{i}\nabla f(\mathbf {\mu} _{i})}, \quad i \in \mathbb{N} \]
위의 수식에서 \(\gamma _{i}\)은 탐색을 할 때 움직이는 거리 (step size)라고 부르고, 딥러닝 분야에서는 나중에 학습률(learning rate)의 개념이 된다. 또한, \(\nabla f(\mathbf {\mu} _{i})\) 부분이 바로 기울기 값을 나타내는 부분이다.
Autograd 기능 없이 기울기 구하기
먼저 torch의 자동 기울기 기능을 사용해서 기울기 값 계산을 하기에 앞서, 계산 결과를 구해보자. \(y\)를 \(\beta\)에 대하여 미분하면 다음과 같다.
\[ \begin{align*} f'(\beta) & =\frac{d}{d\beta}\left(\frac{1}{n}\sum_{i=1}^{n}\left(x_{i}-\beta\right)^{2}\right)\\ & =\frac{1}{n}\sum_{i=1}^{n}\frac{d}{d\beta}\left(x_{i}-\beta\right)^{2}\\ & =-\frac{1}{n}\sum_{i=1}^{n}2\left(x_{i}-\beta\right) \end{align*} \]
따라서 mu값이 2.5로 주어졌을 때, 기울기 값은 다음과 같다.
f_prime <- function(mu, x){
-mean(2*(x - mu))
}
f_prime(2.5, x_tensor)## torch_tensor
## -3.23522
## [ CPUFloatType{} ]이것이 실제로 그러한지 그림을 그려보자.
mu <- 2.5
my_slope <- as.numeric(f_prime(mu, x_tensor))
my_intercept <- as.numeric(f(mu, x_tensor) - f_prime(mu, x_tensor) * mu)
p + geom_abline(slope = my_slope,
intercept = my_intercept, col = "red")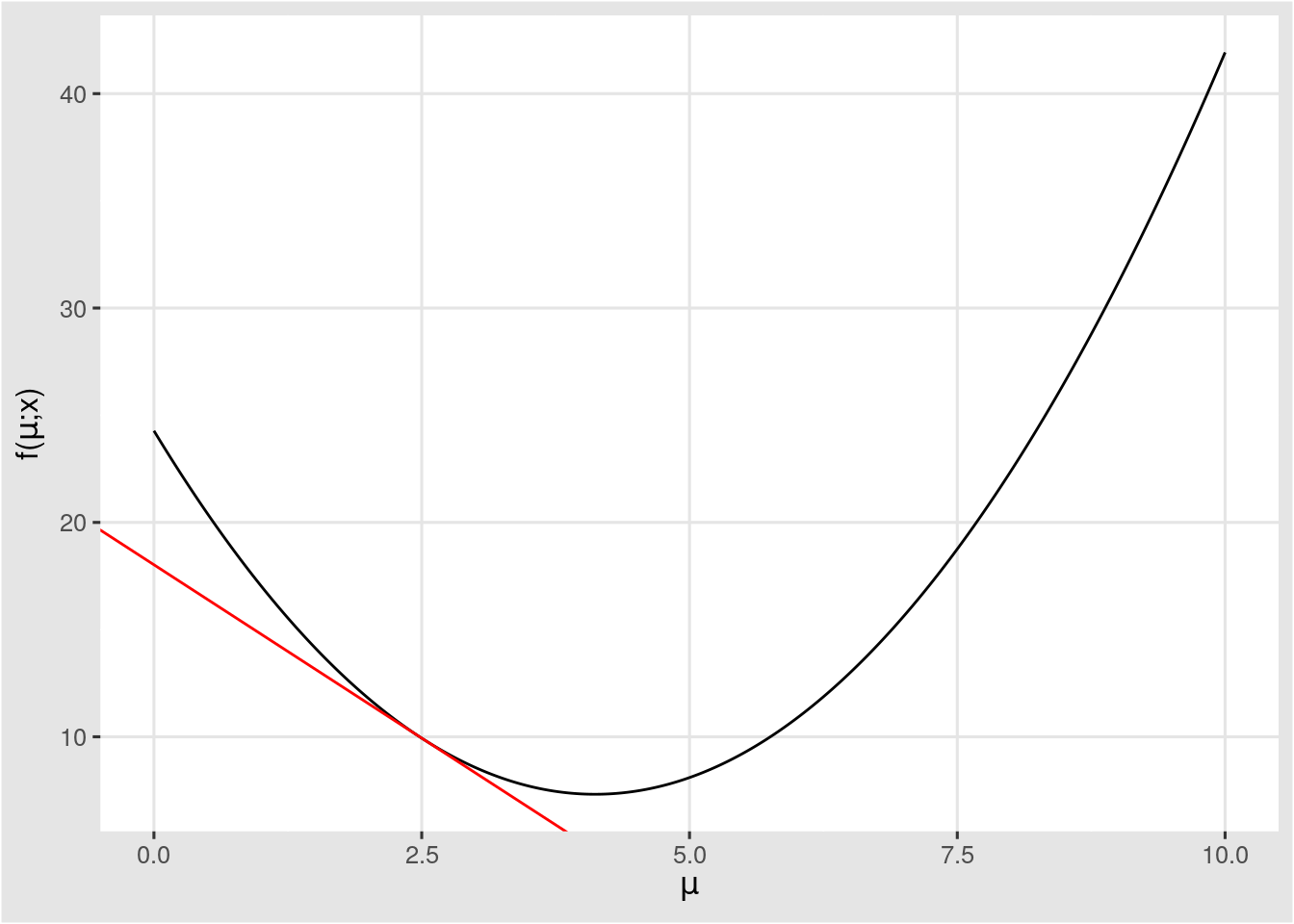
자동 미분(Autograd) 기능
torch에는 우리가 계산한 기울기 구하는 과정들을 자동으로 해주는 기능이 있다. 바로 자동미분 (Auto gradient) 기능이다. 기울기 값 계산을 위해서 해야 할 일은 기울기 계산 기능을 activate 해주는 옵션을 실행시켜주기만 하면 된다.
함수는 \(\mu\)에 대한 함수이므로, 기울기 값을 추적할 텐서 \(\mu\)를 선언할 때 requires_grad = TRUE 옵션을 붙여줘서 선언하면 끝이다. 이 옵션이 활성화되면 torch는 이 변수와 관련된 다른 변수들에 대하여 기울기 값을 자동으로 추적한다. 추후 복잡한 신경망을 다루는 딥러닝 분야에서는 기울기를 구하는 것이 학습에 아주 핵심적인 기능이고, 이러한 기울기를 구하는 이러한 기울기를 계산하는 방법을 역전파 (backpropagation)라고 부른다.
mu <- torch_tensor(2.5, requires_grad=TRUE)
mu## torch_tensor
## 2.5000
## [ CPUFloatType{1} ]mu 텐서가 기울기 추적 옵션을 달고 있어서, 이와 관련되어 생성되는 모든 텐서에 기울기 추적 옵션 grad_fn 태그가 달려서 생성된다. 다음과 같이 y를 정의를 하면, y에도 역시 grad_fn이 붙어서 생성되는 것을 알 수 있다.
y <- mean((x_tensor - mu)^2)
y$grad_fn## MeanBackward0기울기 값 계산을 위해서 해야 할 일은 기울기 계산을 activate 해주는 함수를 실행시켜주기만 하면 된다. y에 대한 베타의 기울기 값을 구하는 것이므로, 다음과 같이 backward()를 이용하여 역전파(backward propagation)를 통하여 기울기 계산을 한다.
y$backward()자동 기울기 추적 기능을 사용한 auto grad가 구한 베타의 기울기 값이 우리가 구한 값과 동일한지 확인해보자.
f_prime(2.5, x_tensor)## torch_tensor
## -3.23522
## [ CPUFloatType{} ]mu$grad## torch_tensor
## -3.2352
## [ CPUFloatType{1} ]앞에서 구한 f_prime(2.5)값이 동일하게 mu$grad에 담겨 있다는 것을 알 수 있다.
자동 미분 관련 함수들
기울기 자동 추적 기능을 사용한다는 것은 그것을 돌리는 컴퓨터의 메모리를 많이 차지한다는 이야기이다. 따라서 우리가 생각하는 변수에 대한 것에만 추적 옵션을 붙여야 하고, 더 이상 필요가 없어지면 기능을 꺼주기도 해야 할 것이다. 이러한 자동 미분 추적 기능들을 자유자재로 다루기 위해서 알아두어야 할 함수들이 있다.
$detach()
현재 y는 기울기 자동추적 기능이 붙어있다. 우리가 다음과 같이 y를 사용해서 텐서 z를 생성하면 그 역시 옵션이 딸려 생성이 될 테지만, y 텐서 이후부터는 추적 기능을 사용하고 싶지 않을 때, $detach()를 사용해서 추적기를 떼어낼 수 있다.
y$grad_fn## MeanBackward0z <- y^2
z$grad_fn## PowBackward0z$detach_()## torch_tensor
## 98.7247
## [ CPUFloatType{} ]z$grad_fn## NULL$requires_grad 변수와 $requires_grad_(TRUE)
이 함수는 이미 선언된 텐서에 미분 추적 기능을 붙이고 싶을 때, $requires_grad_(TRUE)을 사용할 수 있다. 일반 텐서 a를 생성하도록 하자.
a <- torch_tensor(c(1, 2))
a## torch_tensor
## 1
## 2
## [ CPUFloatType{2} ]a$requires_grad## [1] FALSEa$requires_grad 값이 FALSE라는 말은 a에 대한 추적 옵션은 현재 꺼져있는 상태이다. 자동 추적 기능이 없이 생성된 텐서에 추적 기능을 붙일 때에는 a$requires_grad을 TRUE로 바꿔주면 된다. TRUE를 직접 할당해도 되고, $requires_grad_(TRUE)을 사용하여 바꿔줘도 된다.
# a$requires_grad <- TRUE
a$requires_grad_(TRUE)## torch_tensor
## 1
## 2
## [ CPUFloatType{2} ]with_no_grad({})
만약 특정 코드를 실행함에 있어서 추적 기능을 떼고 계산하고 싶은 경우, with_no_grad({})가 유용하다.
y## torch_tensor
## 9.93603
## [ CPUFloatType{} ]y$grad_fn## MeanBackward0with_no_grad({
y
y$grad_fn
})## MeanBackward0경사 하강법
이왕 자동 미분 기능을 알았으니, 이 기능을 이용하여 경사 하강법을 구현하여 함숫값을 최소로 만드는 \(\mu\) 값을 찾아보도록 하자.
learning_rate <- 0.1
# 시작값 0.5
mu <- torch_tensor(0.5, requires_grad=TRUE)
result <- rep(0, 100)
result[1] <- as.numeric(mu)
for (i in 2:100) {
result[i] <- as.numeric(mu)
y <- mean((x_tensor - mu)^2)
y$backward()
with_no_grad({
mu$sub_(learning_rate * mu$grad)
mu$grad$zero_()
})
}
tail(result)## [1] 4.117608 4.117608 4.117608 4.117608 4.117608 4.117608mu$grad$zero_() 부분은 미분 값을 초기화해주는 부분이라고 이해하면 좋다. 그렇지 않을 경우, 이전의 값이 남아있어서 계속 누적되므로 주의하자.
시각화
mu_points <- tibble(x = result,
y = map_dbl(result, ~as.numeric(f(mu = .x, x = x_tensor))))
p +
geom_point(data = mu_points, aes(x = x, y = y), col = "blue")
이 챕터의 제일 첫 부분에서 말했든 이론적인 정답은 데이터의 표본 평균이 함숫값을 최소로 만드는 값이다. 실제로 그렇게 나왔는지 확인해보면 두 값이 같다는 것을 알 수 있다.
result[100]## [1] 4.117608x_tensor$mean()## torch_tensor
## 4.11761
## [ CPUFloatType{} ]이것으로 자동 미분 기능에 대하여 알아보았다. 이 기능을 활용하면 훨씬 복잡한 구조의 함수(예를 들어 딥러닝에서의 신경망 같은)에 대한 미분 값 역시도 쉽게 구할 수 있다. 응용 코드들은 신경망 예제에서 다루기로 하자.
'R' 카테고리의 다른 글
| 8강. 첫 torch 신경망 학습하기 (0) | 2021.11.08 |
|---|---|
| 7강. torch_nn 모듈로 첫 신경망 정의하기 (0) | 2021.11.08 |
| 5강. 데이터 프레임 가지고 놀기 (0) | 2021.10.09 |
| 4강. R 리스트 완전 정복하기 (0) | 2021.10.09 |
| R tidyverse 마스터 클래스 - 1강. dplyr 패키지 기초동사 학습하기 (4) | 2021.10.07 |




댓글