이전에 Coursera에서 Statistical Inference(통계적추론) 수업을 들으면서, 완강 후에 수업에 나오는 개념들에 대해 다시 공부해봐야겠다고 생각했어요. 그래서 수강했던 수업을 훑어보며 이제까지 배웠던 통계학의 기본 개념들을 정리하는 시간을 가져보기로 하였습니다. 👩💻

통계적 추론 (Statistical Inference)
통계학을 이용하여 모집단(population) 내에서 추출한 표본(sample)을 통해 모수(parameter)를 추론하는 과정. 모집단에 대한 추론을 100% 확신하기 위해서는 모집단 전체를 표본으로 조사해야 하지만, 경제성 또는 시간, 양적 접근의 한계 등의 이유로 불가능한 경우가 많기 때문에 표본에서 얻은 정보를 통해 추론한다.
Statistical Inference is the process of drawing formal conclusions from data.확률 (probability)
PMF (Probability Mass Function), PDF (Probability Density Function), CDF (Cumulative Distrivution Function)의 개념에 대해서 헷갈리는 부분이 있었기 때문에 R로 Plot을 그려보며 다시 개념을 생각해보았어요. (혹시 내용 중에 틀린 부분이나 피드백이 필요한 부분이 있다면, 댓글로 남겨주세요.🙋 )
Probability(확률)의 공리적 정의
러시아 수학자 안드레이 콜모고로프(Kolmogorov)에 의해 도입된 확률 이론.
-
아무것도 발생하지 않을 확률 = 0
-
무언가 발생할 확률 = 1
-
무언가 발생할 확률 = 1 - (발생하지 않을 확률)
-
두 확률이 상호배타적인 경우(mutually exclusive), 둘 중 적어도 하나 이상의 확률이 각각의 확률의 합계이다
-
만약에 event A가 event B의 발생을 의미한다면, A의 발생 확률은 B의 발생 확률보다 작다.
-
두 사건의 경우 적어도 하나의 발생 확률은 확률의 합에서 교차점을 뺀 것이다.
\[ \begin{equation} \begin{aligned} P(A_1 \cup A_2) &= P(A_1) + P(A_2) - P(A_1 \cap A_2) \\ &= \text{Sum of the two Prob.} - \text{Prob. of having both} \end{aligned} \end{equation} \]
확률변수 (Random Variable)
실험의 수치적 결과를 의미함. 시행의 결과에 따라 값이 결정되는 변수를 나타낸다. 이산확률변수(Discrete Random Variables)와 연속확률변수(Continuous Random Variable)로 구분할 수 있다.
-
이산확률변수(Discrete Random Variable): Random Variables의 범위가 셀 수 있거나(countable) 특정 값을 취할 가능성에 대해 이야기할 수 있는 것. 무슨 이야기냐 하면, 확률 변수의 값이 연속적인 값이 아닌 이산적인 값을 가지면 이산확률변수라 함.
Random variables that take on only a countable number of possibilities and we talk about the probability that they take specific values
예: 동전던지기에서 앞, 뒤가 나오는 것 주사위를 던져 나오는 결과
-
연속확률변수 (Continuous Random Variables): 범위 내에 모든 실수 값을 취할 수 있는 확률변수. 변수의 값이 실수 집합처럼 연속적이고 무한개의 경우의 수를 가지는 경우.
Continuous random variable can conceptually take any value on the real line or some subset of the real line and we talk about the probability that they line within some range
예: 특정 날짜에 웹 사이트 트래픽, 기준 측정치부터 4년 동안의 BMI 수치, 광고를 클릭한 사람들의 수, 표본 집단 아이들의 아이큐 수치
확률질량함수 (Probability Mass Funcion; PMF)
이산확률 변수에서 특정 값에 대한 확률을 나타내는 함수.
-
항상 0보다 크거나 같아야 한다
-
변수의 가능한 값들의 합은 최대 1이어야 한다
#PMF
x <- c(0:3)
y <- c("0.2", "0.3", "0.3", "0.2")
plot(x, y, type = "h", lwd = 3, col = 4, lty = 5,
main="PMF example",
ylab = "probability mass")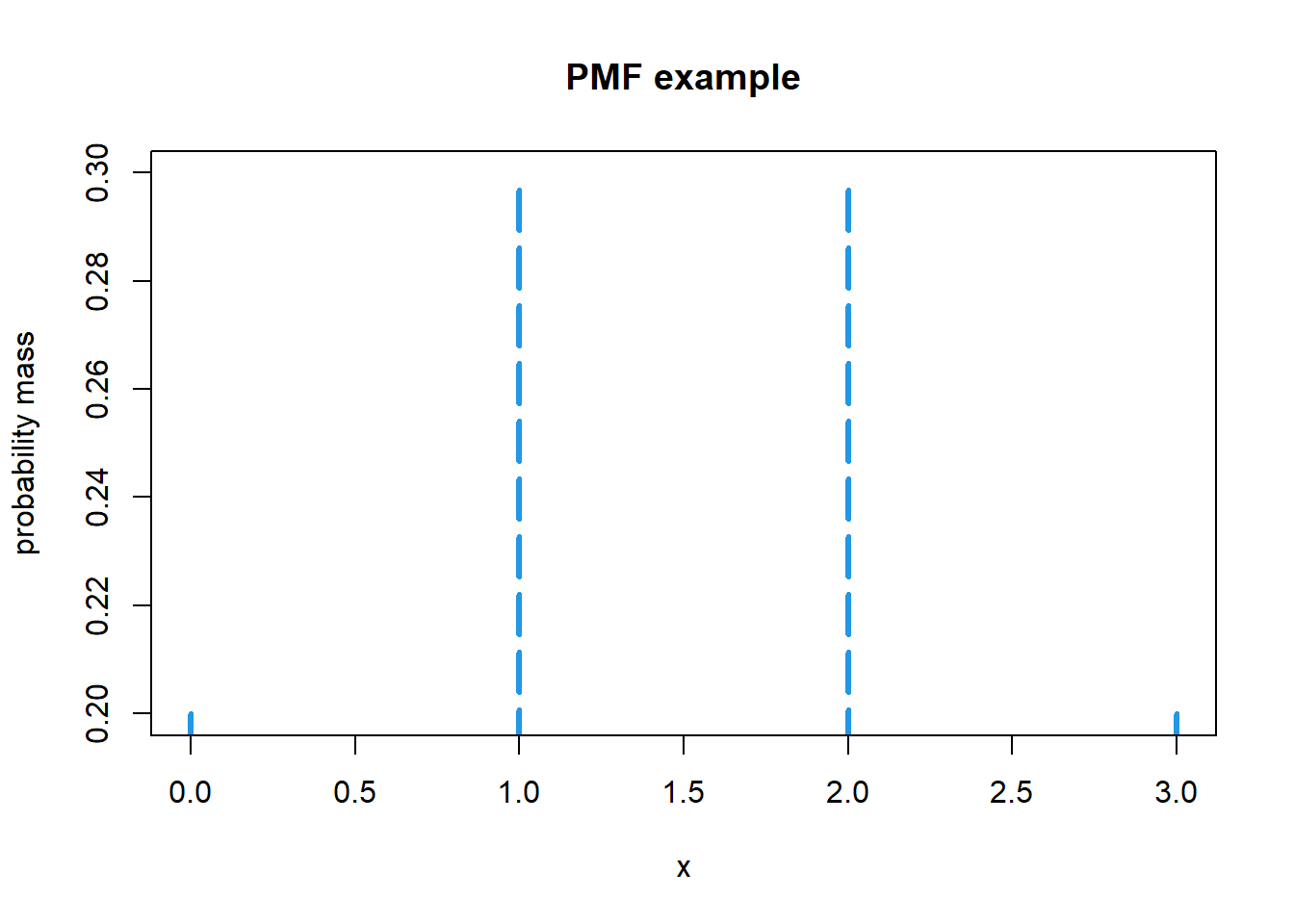
확률밀도함수 (Probability Densicy Function; PDF)
이산확률 변수에서 특정 값에 대한 확률을 나타내는 확률 밀도 함수. 특정 확률 변수 구간의 확률이 다른 구간에 비해 상대적으로 얼마나 높은가를 나타내며, 그 값 자체가 확률은 아님. (특정 구간에 속한 넒이=특정 구간에 속할 확률)이 되도록 정한 함수.
-
항상 0보다 크거나 같아야 한다
-
총 범위(total area)의 값은 반드시 1이어야 한다
# PDF X~N(0,1)
x <- seq(-3, 3, by = 0.1)
plot(x, dnorm(x, mean = 0, sd = 1),
type = "l", lwd = 3, col = 4,
main="PDF of X ~ N(0,1)",
ylab = "density")
누적확률밀도함수 (Cumulative Distribution Function; CDF)
랜덤 변수가 특정 값보다 작거나 같을 확률을 나타내는 함수. 특정 값보다 작은 값들의 확률을 모두 누적해서 구한다는 의미이다. (이 정의는 변수가 이산적이거나 연속적인 것과 관계없이 정의된다)
# CDF X~N(0,1)
x <- seq(-3, 3, by = 0.1)
plot(x, pnorm(x, mean = 0, sd = 1),
type = "l", lwd = 3, col = 4,
main="CDF of X ~ N(0,1)",
ylab = "density")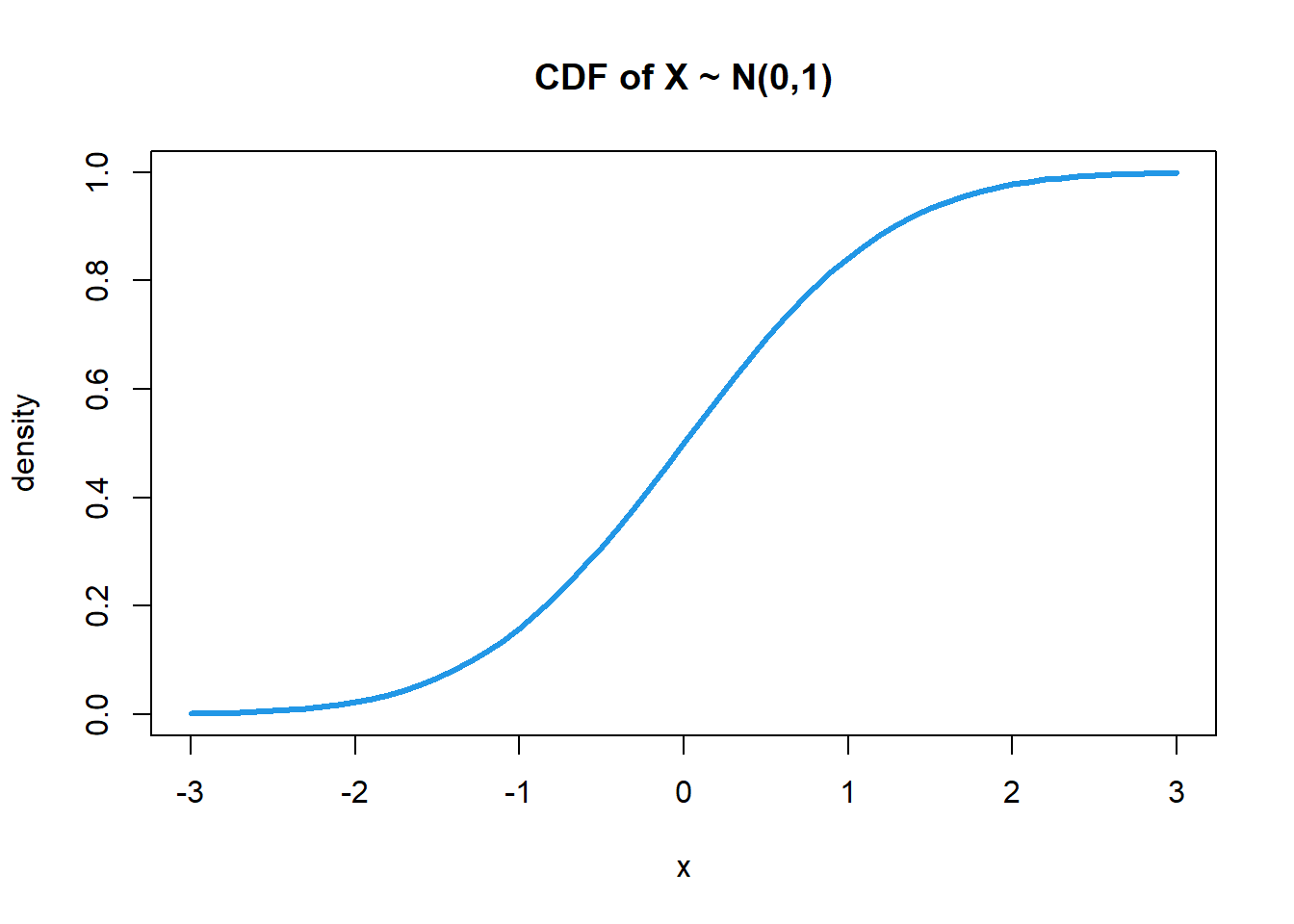
생존함수 (Survival Function)
랜덤 변수가 특정 값보다 큰 경우의 확률을 구하는 함수로 정의됨.
\[ \begin{equation} S(x) = P(X > x) = 1 - P(X \le x) = 1 - F(x) \end{equation} \]
분위수 (Quantile)
확률 분포를 동등한 확률 구간으로 나누는 구분 눈금들(Cut-Points)이라고 정의된다. 또는 어떤 관찰된 샘플 데이터를 동등한 범위들로 잘라내는 구분자이다. 예를 들어, 사분위수(Quartile)을 많이 사용하는데, 4-Quantile이라 생각하면 샘플 데이터를 4개의 동등한 구간으로 잘라내기 위한 구분자는 3개가 된다. Q1, Q2, Q3와 같이 표현한다. q-Qunatile은 유한요소집합을 q개의 동등한 부분집합으로 구분해주는 눈금자이다.
A Percentil은 단순하게 퍼센트로 표현된 quantile이다.
-
2-quantile = median(둘로 나눈 것의 중앙값)
-
4-quantile = quartiles (대문자 Q를 사용)
- Q1 = 1st-quartiles
- Q2 = 2nd-quartiles
- Q3 = 3rd quartiles
- Q3-Q1을 interquartile range(IQR) 또는 midspread 혹은 middle fifty라 함
-
10-quantiles = deciles -> D
-
100-quantiles = percentiles -> P
-
Median (중앙값): 전체 데이터 중 가운데에 있는 수
개인적으로 Quantile, Median, InterQuarile, Variance 등 기본 개념에 대해서는 Inflean에 있는 찐슬통이님의 강의(R로 배우는 통계)를 듣고 쏙쏙 이해하게 됐었어요. 혹시 저처럼 기본 개념을 글로 봐도 잘 모르시겠다는 분들이 계시면 이 강의 도움될 것 같아 추천드려요! 👩🎓🌟
필자 소개
📝 찐슬통이님이 업로드해주신 집필진 소개를 참고해주세요
활동 장소
✨ 개인 블로그입니다 connie-n.tistory.com/
connielog
connie-n.tistory.com
댓글